

Transforma documentos no estructurados en datos accionables con IA conversacional. Reduce hasta un 90% en costos y tiempo de desarrollo con nuestra plataforma de IA empresarial. Una solución completa que democratiza el acceso a la IA avanzada para todo tipo de empresas.
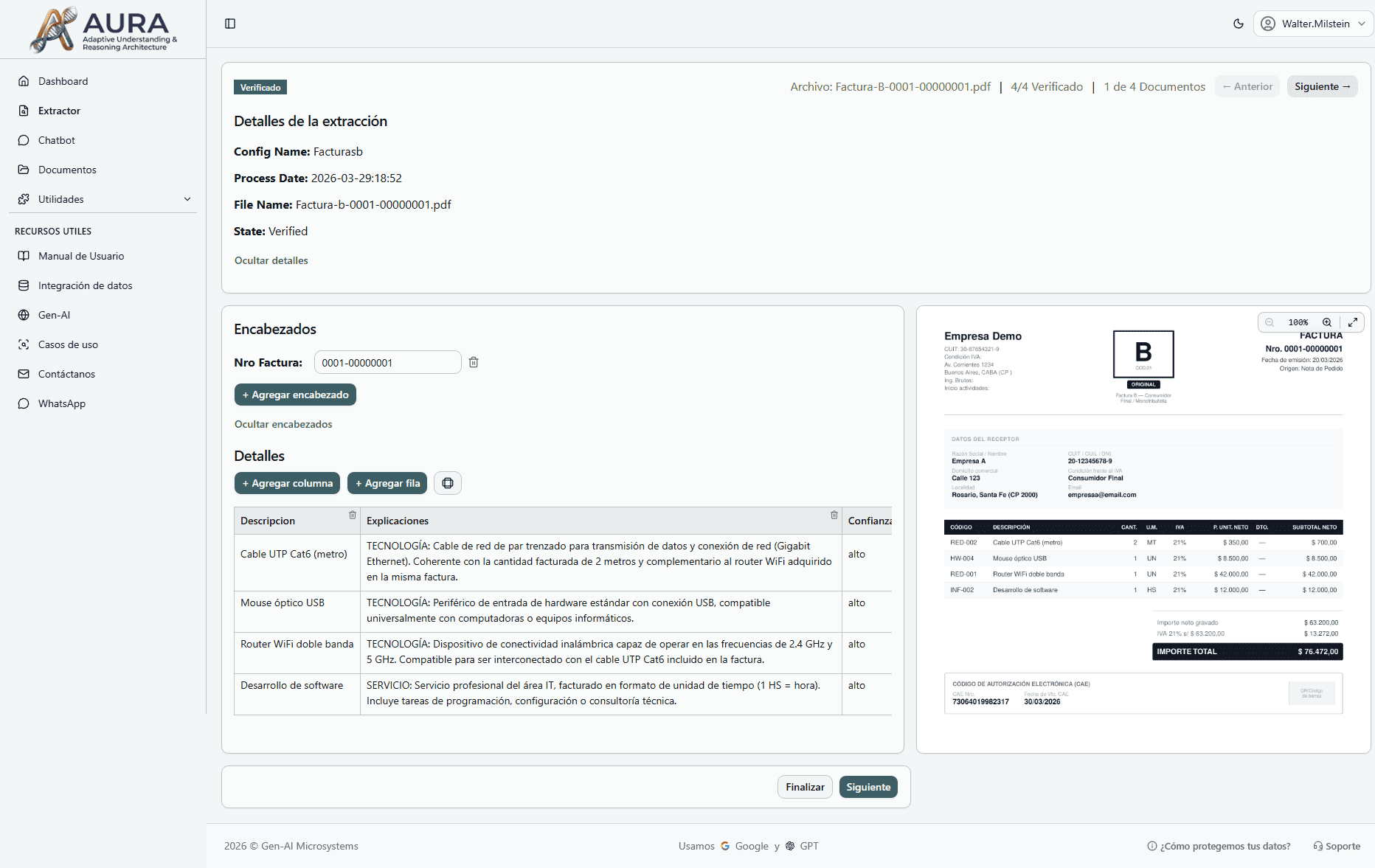
Visión General de MIKA
El Problema del Mercado
Las empresas tienen documentos en silos, datos sin explotar, y herramientas fragmentadas. Los competidores ofrecen soluciones parciales: unos extraen datos, otros hacen chat, otros escalan. Nadie integra todo.
La Solución MIKA
MIKA es la única plataforma que combina tres capas tecnológicas en una solución integrada:
IA Generativa (LLMs)
Para entender, conversar y extraer información de documentos
ML Tradicional
Para predecir, clasificar, detectar anomalías y tomar decisiones
Big Data
Para escalar a millones de documentos con Spark, Databricks y Hadoop
El Diferenciador Único
De documentos a decisiones. Extrae con IA generativa, analiza con ML, escala con Big Data.
Las Tres Capas de MIKA
CAPA 1: IA GENERATIVA
- •RAG / Chat
- •Extracción OCR
- •Resumen
- •Traducción
- •Q&A sobre docs
- •Generación
¿Qué dice este contrato?
CAPA 2: ML TRADICIONAL
- •Clasificación automática
- •Predicción numérica
- •Detección de anomalías
- •Clustering inteligente
- •Series temporales
- •Interpretabilidad
¿Es este documento fraudulento?
CAPA 3: BIG DATA
- •Apache Spark
- •Databricks
- •Hadoop
- •Kafka
- •Delta Lake
- •Procesamiento batch
Procesa 10M docs
Flujo de Datos Integrado
El flujo natural del dato en MIKA:
Capa 1: IA Generativa (LLMs)
Potencia de modelos de lenguaje avanzados para entender, conversar y extraer información de documentos
Capacidades Core
RAG (Retrieval)
Búsqueda semántica en documentos. Pregunta en lenguaje natural y obtén respuestas con contexto.
Chat Documental
Conversa con tus archivos como si fueran un experto. Ideal para contratos, manuales, políticas.
OCR Avanzado
Lee manuscritos con 98.5% de precisión. Ningún otro sistema alcanza esta exactitud.
Extracción de Datos
Extrae campos estructurados de facturas, contratos, formularios automáticamente.
Multi-LLM
Orquestación de Claude, GPT, Gemini, Llama. Usa el mejor modelo para cada tarea.
80 Idiomas
Procesa documentos en cualquier idioma sin configuración adicional.
Pseudoanonimización
Protege datos sensibles antes de enviarlos a LLMs externos. Compliance desde día uno.
Chat con SQL
Pregunta "¿cuántas facturas de más de €10K?" y MIKA genera el query automáticamente.
Multi-LLM: El Mejor de Cada Modelo
MIKA orquesta automáticamente múltiples modelos de lenguaje (Claude, GPT-4, Gemini, Llama) eligiendo el más adecuado para cada tarea. Obtienes el mejor resultado sin preocuparte por la complejidad técnica.
Capa 2: Machine Learning Tradicional
Por qué ML Tradicional cuando tienes LLMs?
Los LLMs son excelentes para entender y generar texto, pero los modelos tradicionales son superiores para:
Predicción numérica
Scoring de riesgo, probabilidad de impago, churn
Clasificación rápida
Tipo de documento en milisegundos, no segundos
Detección de anomalías
Fraude, documentos alterados, valores atípicos
Interpretabilidad
Explicar por qué un contrato es riesgoso (requerido por reguladores)
Costo
Inferencia 100x más barata que LLMs para tareas repetitivas
Catálogo de Modelos Disponibles
Random Forest
Qué es:
Ensemble de árboles de decisión que vota por mayoría. Robusto y preciso.
Parámetros clave:
n_estimators (100-500), max_depth (10-30), min_samples_split
Caso MIKA:
Clasificar tipo de documento (factura, contrato, póliza) con 95%+ precisión.
Ventaja:
Interpretable (feature importance), maneja datos faltantes
XGBoost
Qué es:
Gradient boosting optimizado. El estándar de oro en competiciones Kaggle.
Parámetros clave:
learning_rate (0.01-0.3), max_depth (3-10), n_estimators, subsample
Caso MIKA:
Scoring de riesgo de contratos. Probabilidad de litigio.
Ventaja:
Máxima precisión, maneja desbalanceo de clases, GPU support
LightGBM
Qué es:
Gradient boosting de Microsoft. Más rápido que XGBoost en datasets grandes.
Parámetros clave:
num_leaves, learning_rate, feature_fraction, bagging_fraction
Caso MIKA:
Clasificación masiva de millones de documentos en batch.
Ventaja:
10x más rápido que XGBoost, menor consumo de memoria
20+ Algoritmos de ML a Tu Alcance
MIKA incluye más de 20 algoritmos de machine learning listos para usar en tus documentos. Desde clasificación simple hasta redes neuronales avanzadas, todo integrado en una plataforma.
Capa 3: Big Data & Escala
Integración nativa con las principales plataformas de Big Data del mercado
Integraciones de Big Data
Apache Spark
Capacidad:
Procesamiento distribuido en memoria. Hasta 100x más rápido que MapReduce.
Caso de Uso:
Procesar 10M+ facturas en horas. Extracción masiva. ETL documental.
Databricks
Capacidad:
Lakehouse unificado. Analytics + ML + BI en una plataforma.
Caso de Uso:
Pipeline completo: ingestar docs → extraer → analizar → dashboards.
Hadoop HDFS
Capacidad:
Almacenamiento distribuido. Petabytes de datos.
Caso de Uso:
Archivo histórico de documentos. Data lake documental.
Apache Kafka
Capacidad:
Streaming en tiempo real. Eventos y mensajería.
Caso de Uso:
Procesar documentos al instante. Alertas de fraude en tiempo real.
Delta Lake
Capacidad:
ACID sobre data lakes. Versionado y time travel.
Caso de Uso:
Auditoría de documentos. Rollback. Compliance histórico.
Apache Hive
Capacidad:
SQL sobre Hadoop. Data warehouse.
Caso de Uso:
Consultas analíticas sobre millones de documentos procesados.
Apache Airflow
Capacidad:
Orquestación de workflows. DAGs programáticos.
Caso de Uso:
Automatizar pipelines de procesamiento documental.
Presto/Trino
Capacidad:
Consultas SQL federadas. Multi-fuente.
Caso de Uso:
Query unificado sobre docs en S3, Hadoop, bases de datos.
Escenarios de Escala
MIKA se adapta a cualquier volumen de procesamiento documental, desde pequeñas empresas hasta corporaciones globales
PYME
Volumen
10K docs/mes
Stack
MIKA Core
Tiempo
Segundos
Enterprise
Volumen
1M docs/mes
Stack
MIKA + Spark
Tiempo
Horas
Mega Corp
Volumen
100M+ docs/mes
Stack
MIKA + Databricks
Tiempo
Batch nocturno
Tiempo Real
Volumen
Streaming
Stack
MIKA + Kafka
Tiempo
Milisegundos
Escalabilidad Sin Límites
MIKA crece contigo. Comienza procesando miles de documentos al mes y escala hasta cientos de millones sin cambiar de plataforma. Una arquitectura, infinitas posibilidades.
El problema que resuelve Mika
Sin Mika
- Tus equipos pierden 8+ horas semanales buscando información en documentos
- Auditar 100 contratos requiere 6 personas y 4 semanas
- No puedes usar ChatGPT con datos sensibles: riesgo de fuga y multas GDPR
- Documentos manuscritos se procesan manual, con 15-20% de errores
- La información está en silos: nadie encuentra lo que necesita
Con Mika
- Búsqueda semántica: encuentra cualquier documento en segundos
- Audita 100 contratos en 10 minutos con 1 persona
- Pseudo Anonimización automática: usa IA sin riesgo de compliance
- OCR manuscrito con 98.5% de precisión
- Todo conectado: Drive, SharePoint, bases de datos, en un solo lugar
Resultado con Mika: 90% menos tiempo • 95% menos errores • 100% compliance
Explora Mika en acción
Navega por todas las funcionalidades de la plataforma
Cómo usar Mika
Automatiza el procesamiento de documentos en pocos pasos
Crea tu configuración personalizada
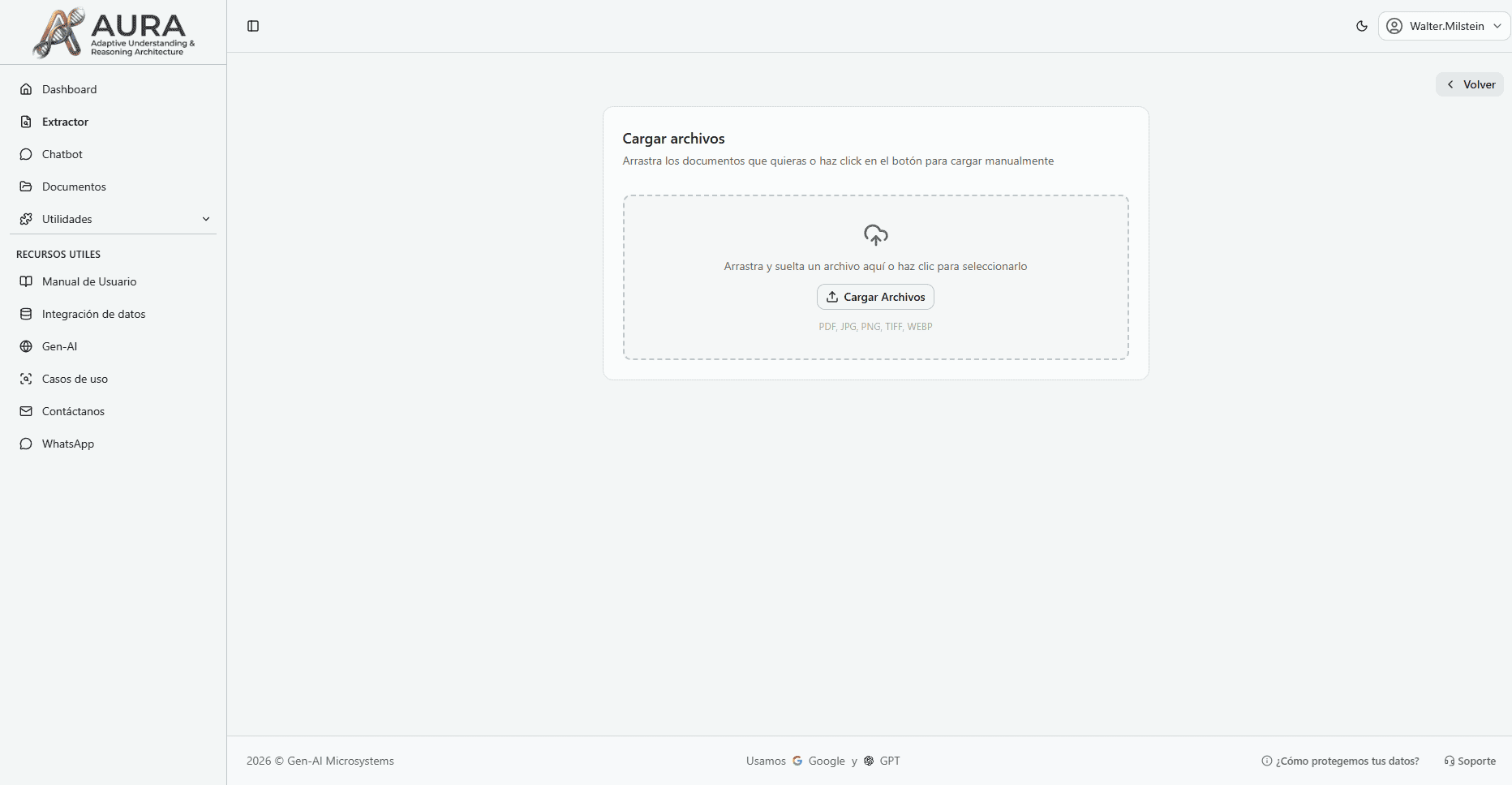
- 1Sube un documento modelo con el formato que deseas procesar.
- 2Selecciona los campos clave que quieres extraer (como monto, fecha o proveedor).
- 3Entrena y guarda la configuración con un nombre descriptivo para usarla cuando quieras.
Ejecuta la extracción masiva
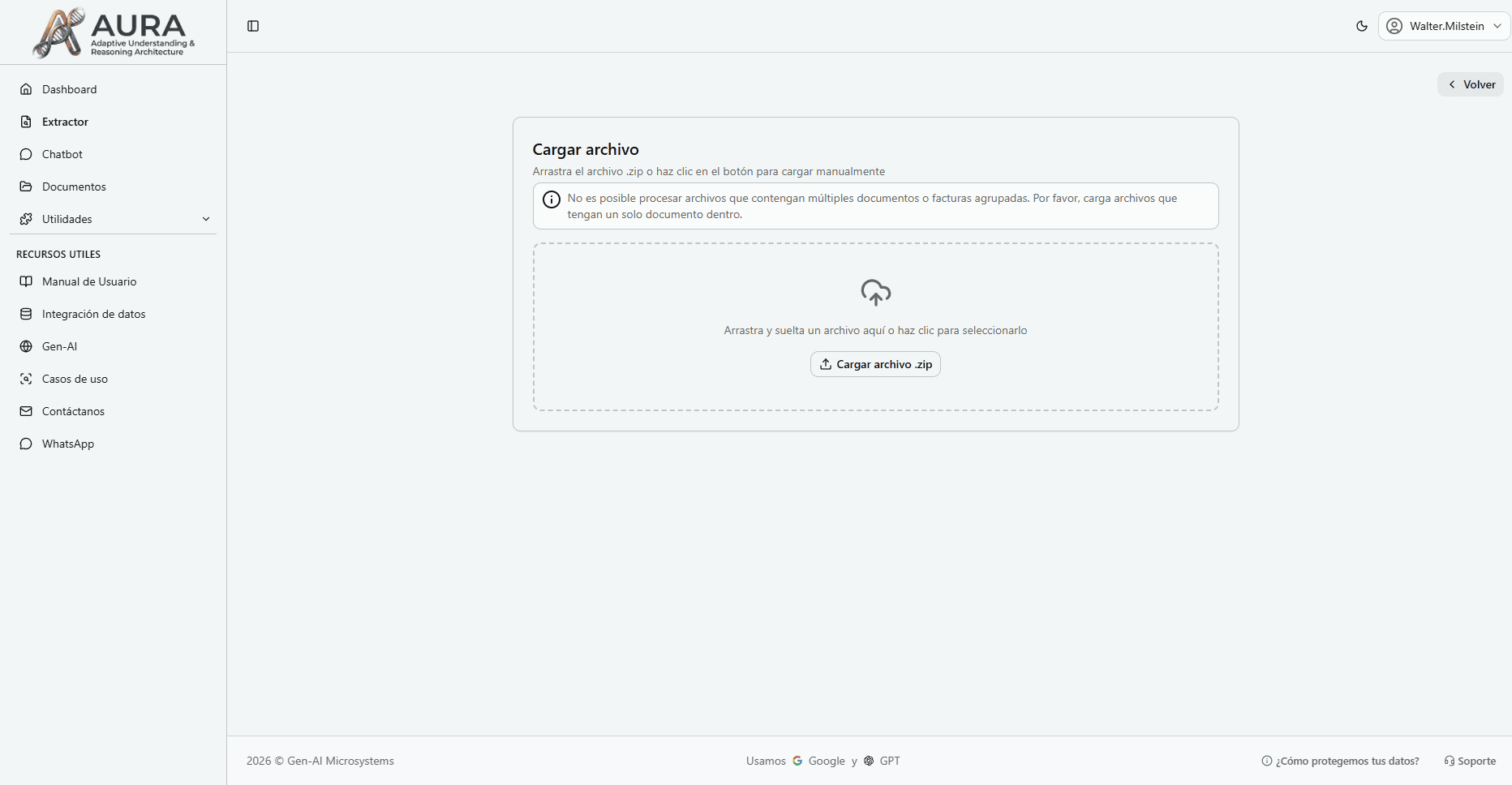
- 1Selecciona la configuración guardada.
- 2Sube un archivo ZIP con múltiples documentos del mismo tipo.
- 3Haz clic en 'Ejecutar' y deja que Mika procese todos los archivos automáticamente.
Revisa y descarga los resultados
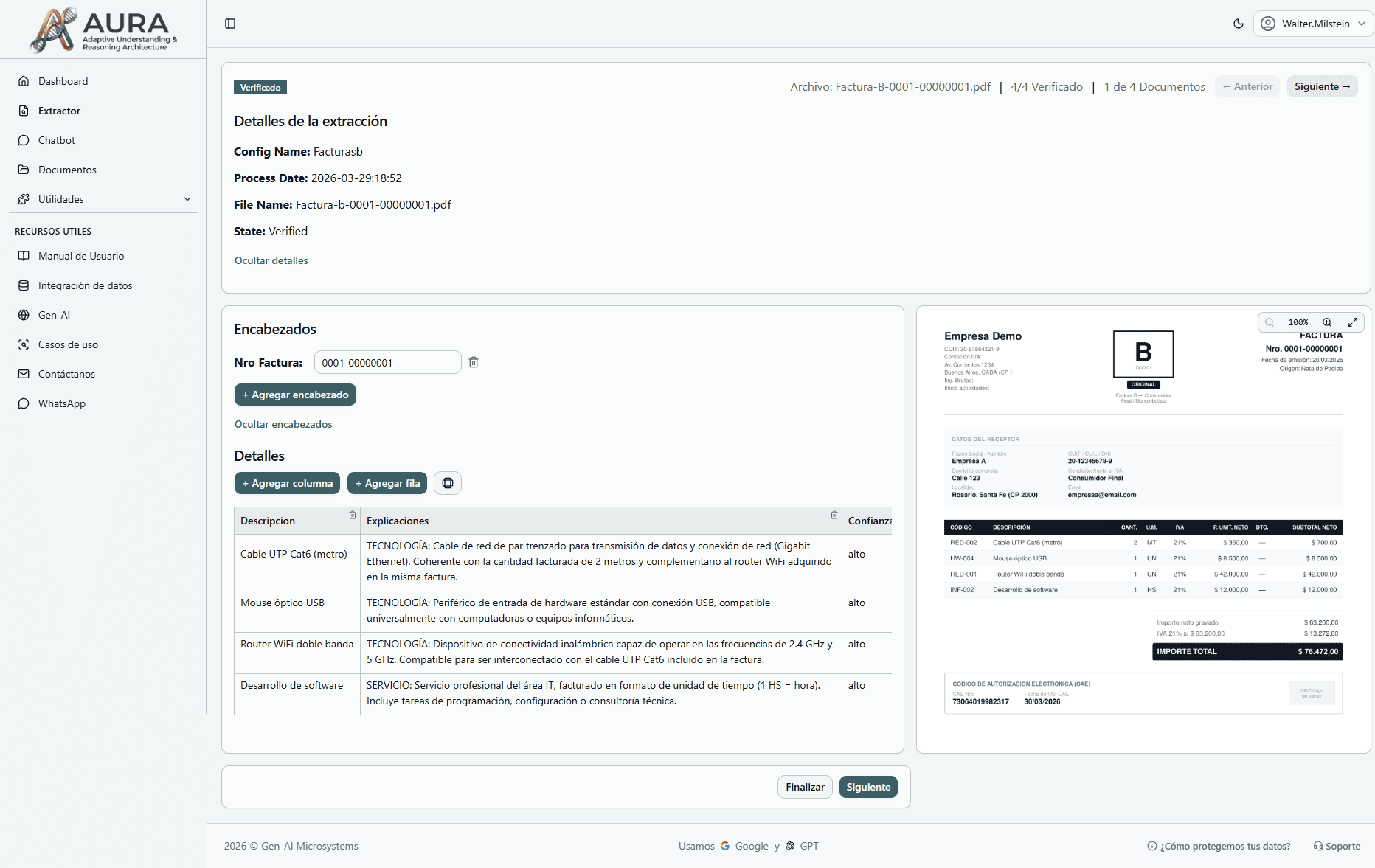
- 1Una vez completado el proceso, accede a los resultados desde la sección correspondiente.
- 2Revisa y corrige manualmente cualquier dato si es necesario.
- 3Descarga los datos extraídos en formato CSV, Excel o JSON para usarlos en otros sistemas.
Cómo usar el chatbot
Configura, entrena y comienza a interactuar en minutos
Crea y entrena tu chat
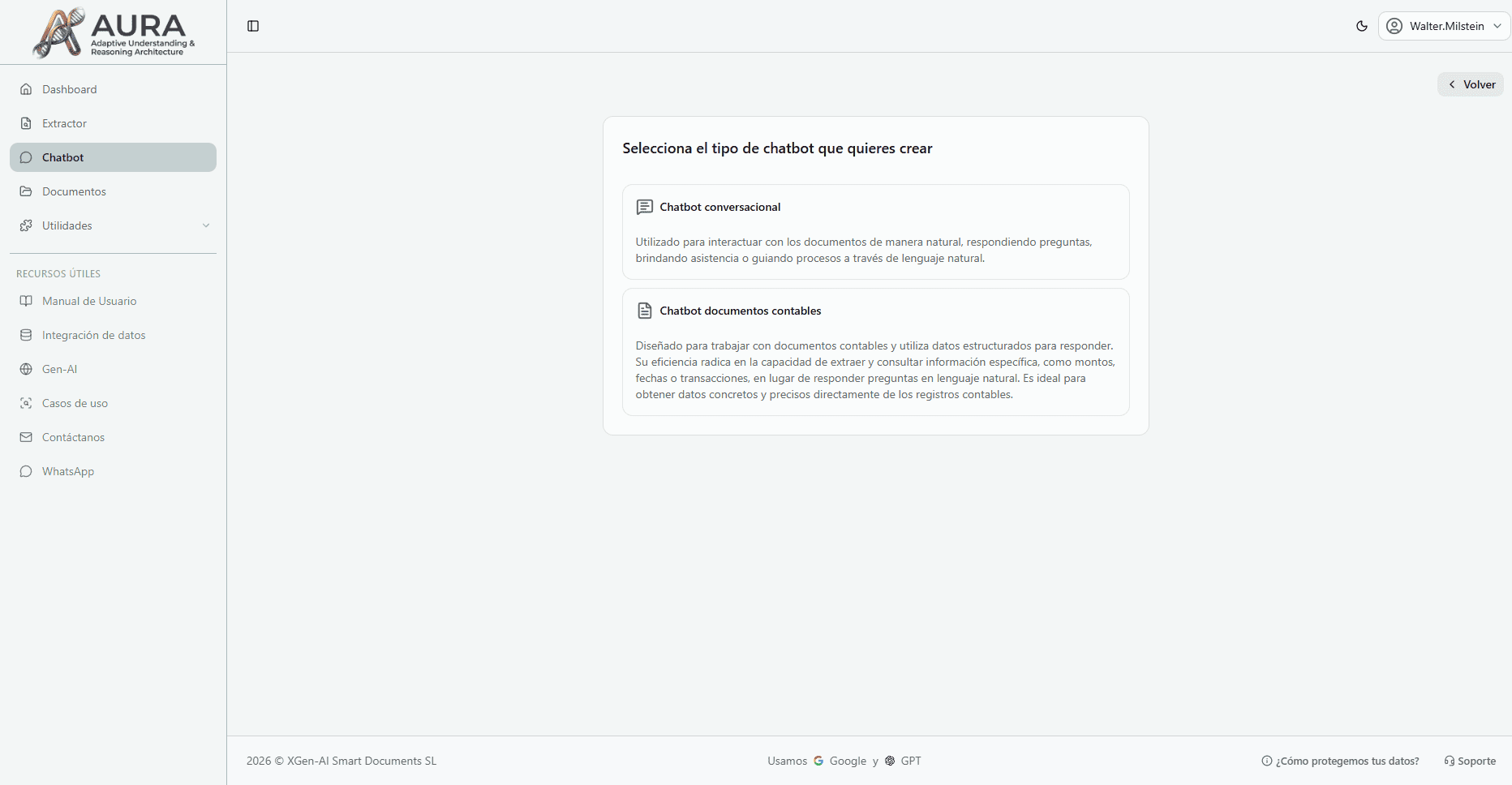
- 1Sube uno o más documentos relacionados con el tema del chat.
- 2Selecciona el tipo de documento en la configuración: Común (legales, cartas, actas) o Estructurado (contables, formularios, reportes financieros).
- 3Asigna un nombre descriptivo al chat y guárdalo para usarlo después.
Interactúa con tu chat
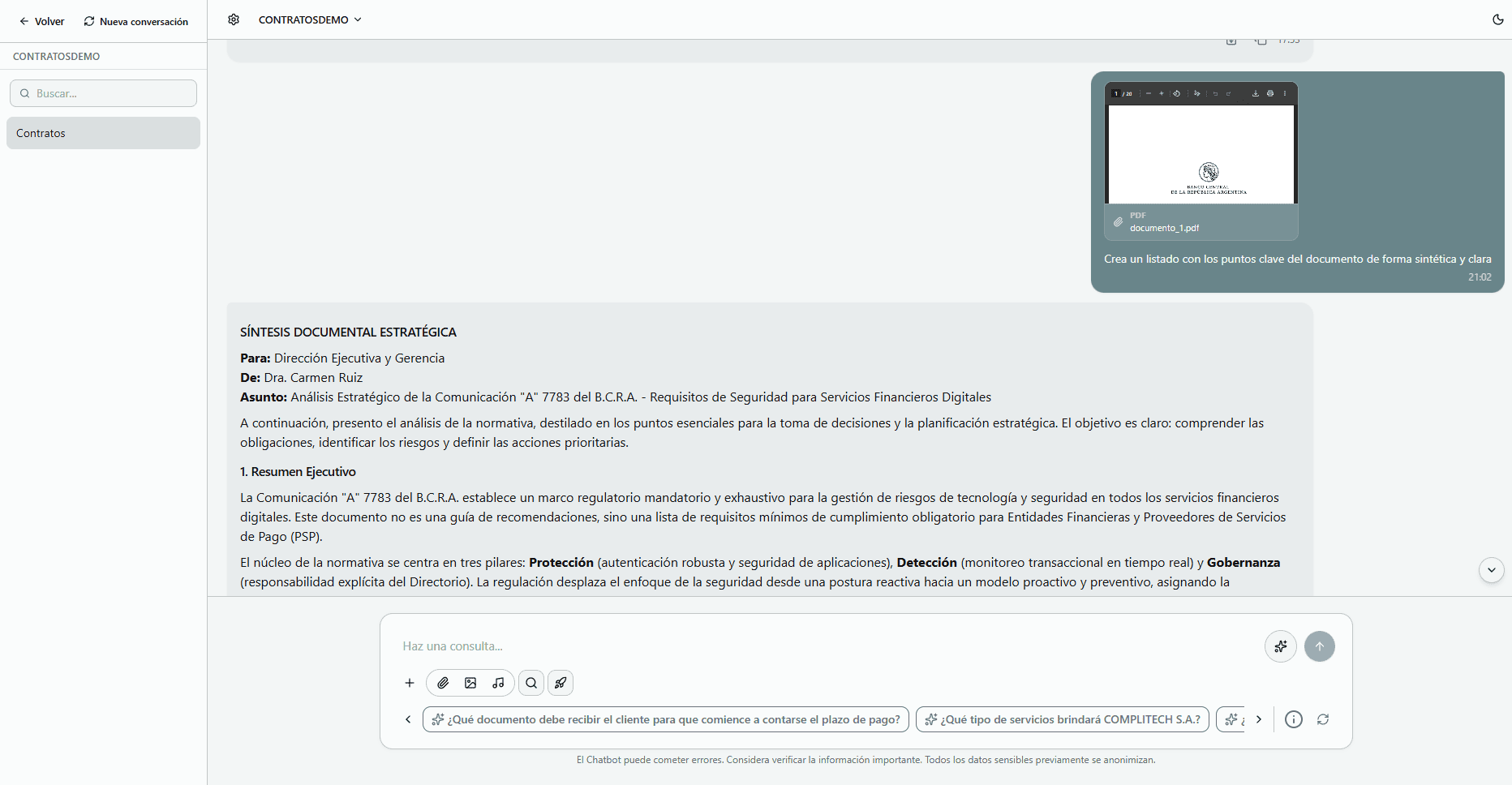
- 1Ingresa al chat desde la lista de chats guardados.
- 2Haz preguntas sobre los documentos cargados usando lenguaje natural.
- 3Solicita acciones específicas como resúmenes, traducciones o comparaciones.
- 4Interactúa con documentos PDF, imágenes y audios.
Usa las preguntas sugeridas por la IA
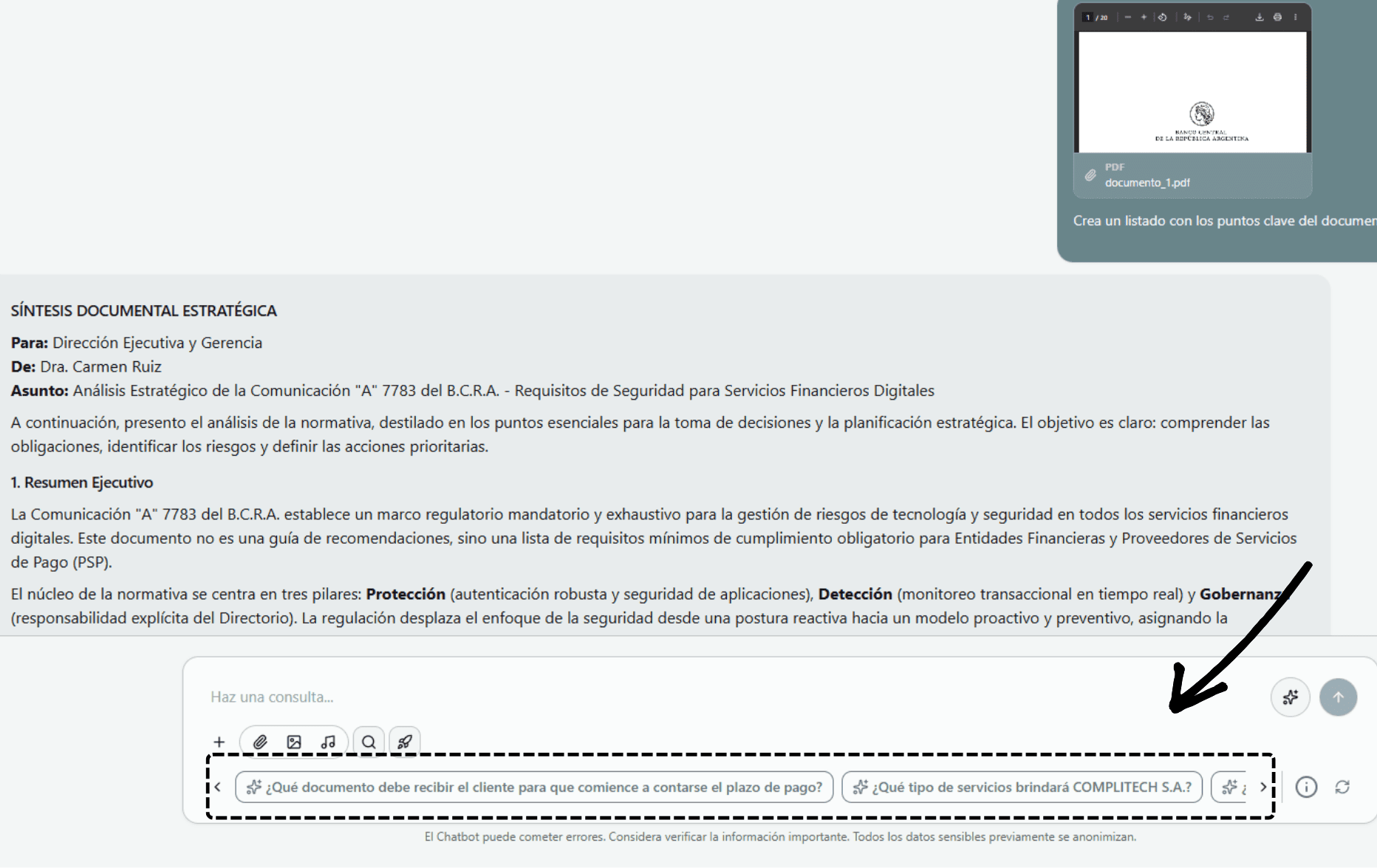
- 1Al abrir un chat, Mika analiza los documentos cargados y genera automáticamente preguntas relevantes.
- 2Haz clic en cualquier pregunta sugerida para iniciar la conversación sin escribir nada.
- 3Las sugerencias se actualizan según el contexto de la conversación y los documentos disponibles.
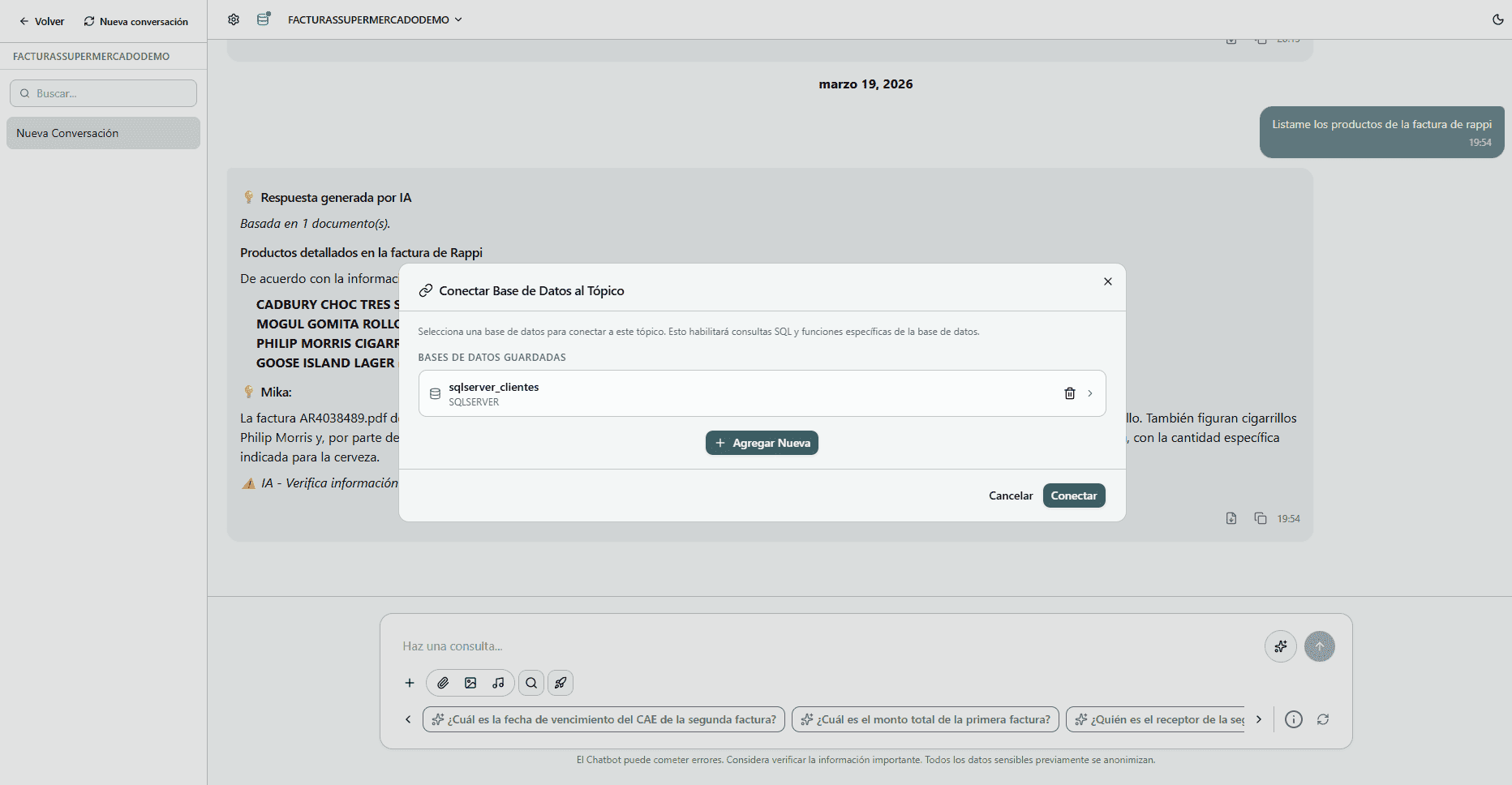
Conecta Mika con tus bases de datos
Mika se integra de forma nativa con tus bases de datos relacionales y no relacionales, abriendo un nuevo nivel de inteligencia sobre tu propia información estructurada.
- Chat sobre tus datos — Consulta tablas, reportes y métricas en lenguaje natural, sin necesidad de saber SQL.
- Extracciones hacia tu BD — Guarda automáticamente los datos extraídos de documentos directamente en tus tablas.
- Contexto enriquecido — Combina documentos e información estructurada en un mismo chat para respuestas más completas.
- Conectores listos — Compatible con PostgreSQL, MySQL, SQL Server, MongoDB y más, sin desarrollo adicional.
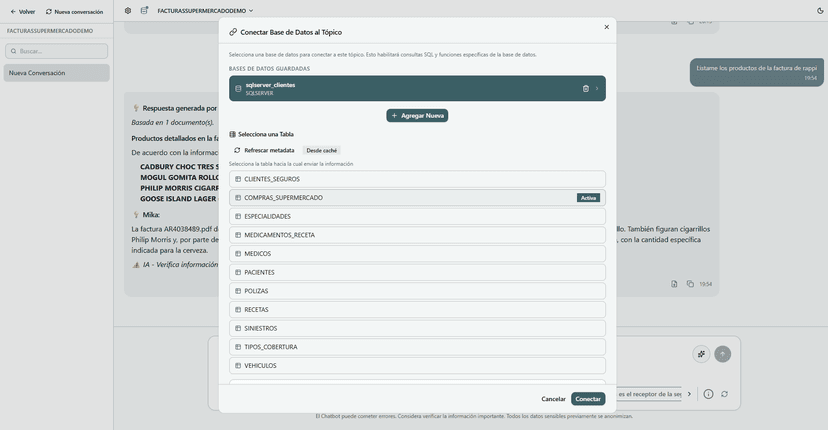
Encuentra cualquier documento con solo describirlo
Olvídate de las carpetas y los filtros. Con Mika puedes escribir lo que necesitas en lenguaje natural y la IA localiza el documento exacto entre miles en segundos.
- Lenguaje natural — Escribe como hablas: 'el contrato de Juan del año pasado' y Mika lo encuentra.
- Búsqueda semántica — No busca palabras exactas, entiende el significado y el contexto de tu consulta.
- Filtros automáticos — Mika detecta fechas, tipos de documento y personas desde tu prompt sin configuración manual.
- Resultados al instante — Ordena y presenta los documentos más relevantes con un resumen de por qué coinciden.
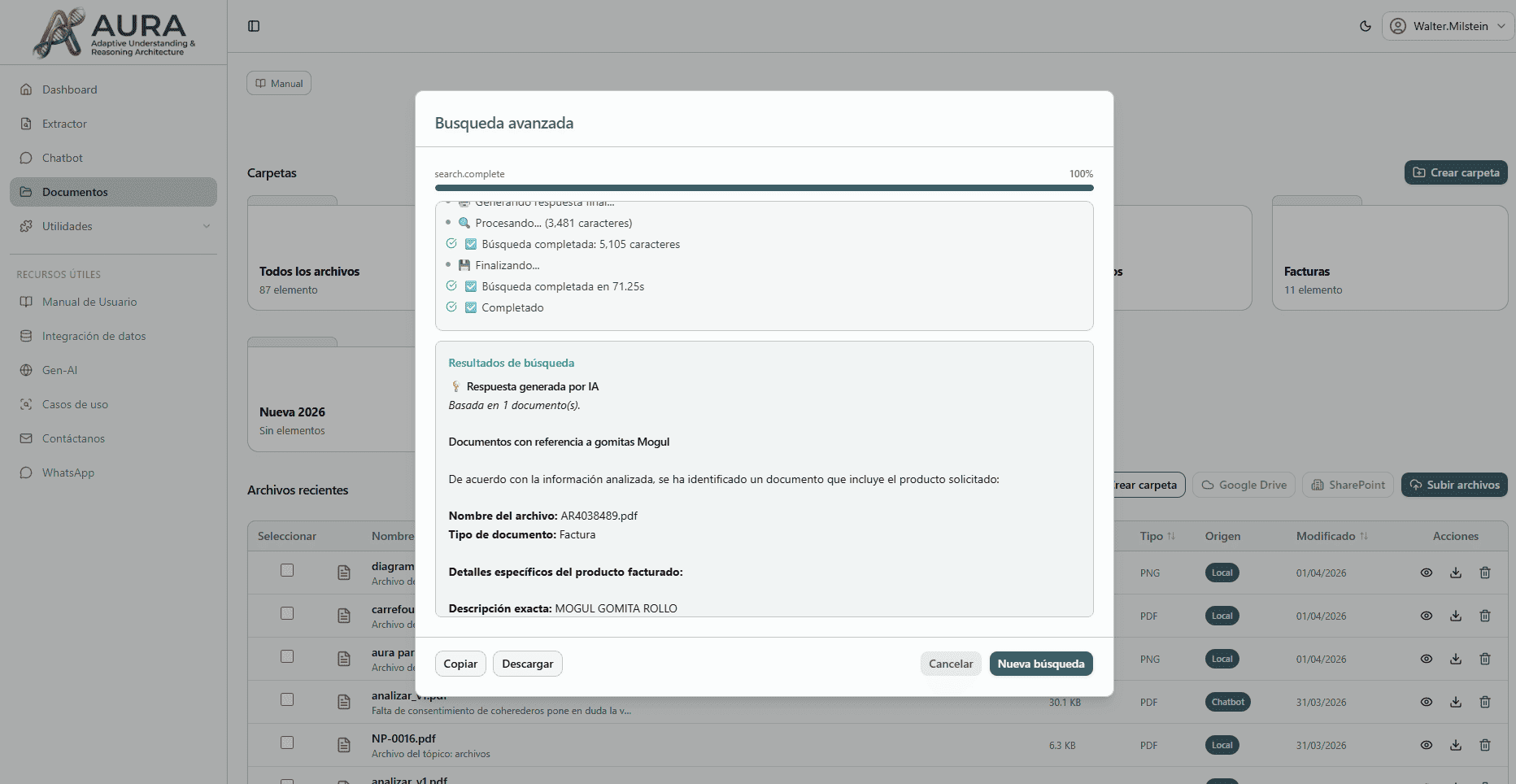

Herramientas para cada tarea
Las utilidades de Mika se dividen en dos grandes bloques: Herramientas, con 17 utilidades para manipular PDFs, imágenes, texto y hacer conversiones; e Inteligencia, con capacidades de búsqueda semántica y razonamiento avanzado sobre documentos.
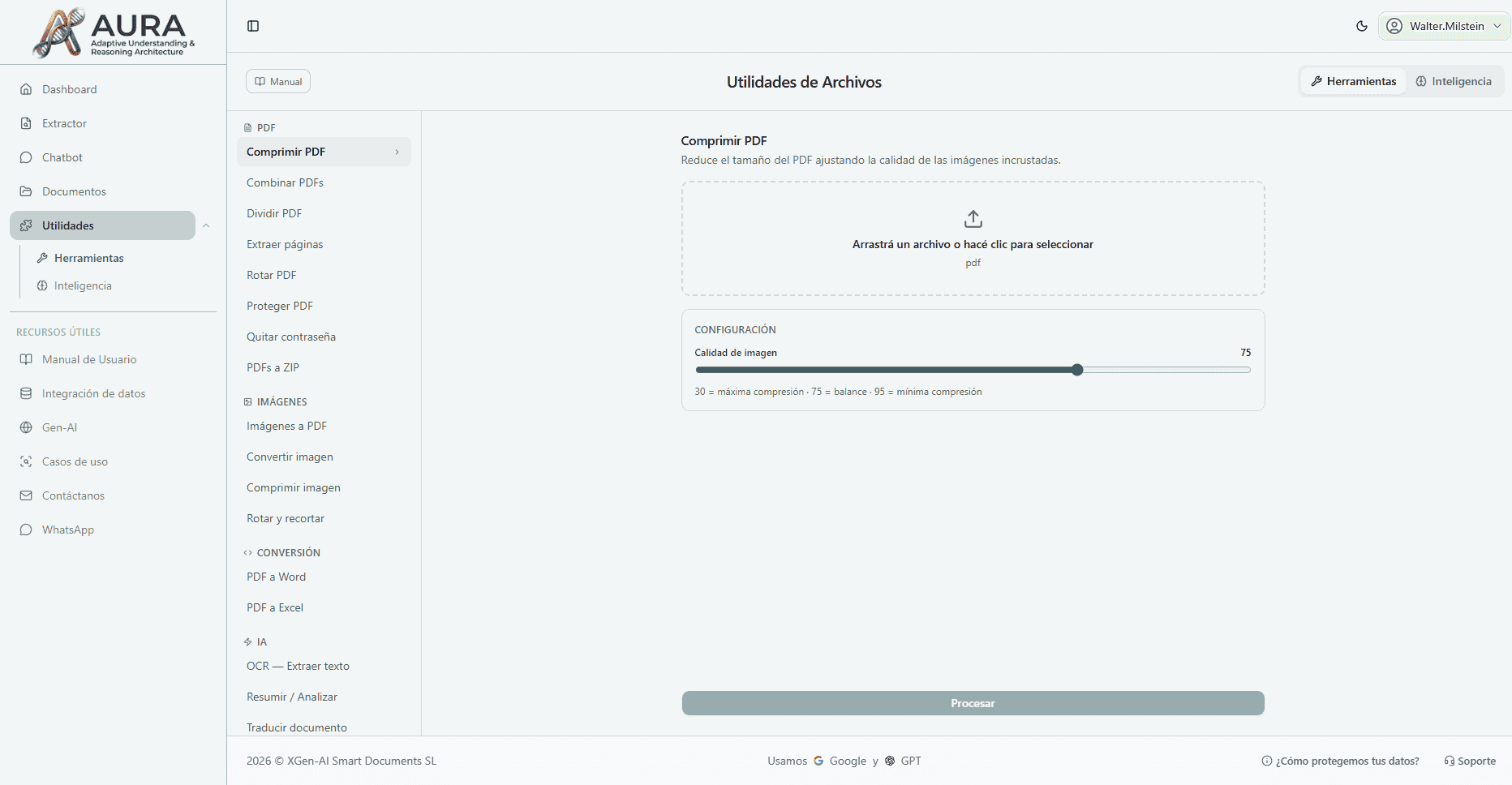
¿Qué es lo que hace Mika?
Extracción Inteligente
Extrae datos de facturas, contratos, formularios automáticamente. 98.5% de precisión incluso en documentos manuscritos.
Gestión Documental
Organiza y accede a tus archivos desde un solo lugar. Conecta con Google Drive y SharePoint sin migrar nada.
IA Conversacional
Pregunta a tus documentos en lenguaje natural. "¿Qué contratos vencen este mes?" MIKA responde con citas exactas.
Dashboard Administrativo
Control total: usuarios, permisos, uso, costos. Métricas en tiempo real del procesamiento documental.
Búsqueda Avanzada
Busca por significado, no por palabras exactas. Encuentra en miles de documentos en segundos.
Procesamiento Masivo
Carga 1.000 documentos y MIKA los procesa en paralelo. Extracción, clasificación y validación automática.
Más de 80 idiomas y dialectos soportados
Mika procesa, extrae y conversa en cientos de idiomas y variantes regionales de todo el mundo.
+164
idiomas y dialectos
Casos de Uso por Industria
Soluciones específicas de MIKA adaptadas a las necesidades de cada sector
Healthcare / Pharma
Historiales clínicos
Solución MIKA:
OCR de manuscritos médicos + extracción de diagnósticos + pseudoanonimización HIPAA
Modelos:
Predicción de readmisión
Solución MIKA:
Analizar historial del paciente y predecir probabilidad de reingreso en 30 días
Modelos:
Farmacovigilancia
Solución MIKA:
Procesar reportes de efectos adversos + clustering de patrones + alertas
Modelos:
Ensayos clínicos
Solución MIKA:
Extraer datos de 10K+ documentos de ensayos + análisis de eficacia
Modelos:
¿Tu Industria No Está Aquí?
MIKA es completamente personalizable para cualquier sector. Contáctanos para diseñar una solución específica para tu industria y casos de uso.
Arquitectura Técnica
Una arquitectura robusta y escalable diseñada para procesamiento documental de nivel empresarial
Diagrama de Arquitectura
CAPA DE ENTRADA
MIKA CORE
MIKA LLM
MIKA ML
MIKA BIG DATA
CAPA DE SALIDA
| Capa | Tecnología |
|---|---|
| Backend | PythonFastAPICeleryRedisPostgreSQLElasticsearch |
| LLMs | Claude APIOpenAI APIGeminiLlama (self-hosted)LangChain |
| ML | Scikit-learnXGBoostLightGBMPyTorchTensorFlowMLflow |
| Big Data | Apache SparkDatabricksHadoopKafkaDelta LakeAirflow |
| Infra | KubernetesDockerAWS/Azure/GCPTerraformPrometheusGrafana |
| Frontend | ReactTypeScriptTailwindCSSChart.jsAG Grid |
Arquitectura de Clase Empresarial
MIKA utiliza las mejores tecnologías del mercado en cada capa. Una arquitectura modular, escalable y probada en producción por empresas de todo el mundo.
Casos de Uso
Healthcare
Documentos: Historiales clínicos manuscritos, recetas escritas a mano, notas de enfermería, informes de laboratorio, imágenes diagnósticas (RX, resonancias, ecografías)
Caso: Digitalización de expedientes manuscritos + estructuración automática de historiales + análisis de imágenes médicas
- OCR Manuscrito → Lee recetas y notas médicas con 98.5% precisión
- Extracción Inteligente → Estructura datos de laboratorio automáticamente
- Análisis de Imágenes → Diagnóstico asistido en placas radiológicas
- Chatbot RAG → "¿Qué pacientes tienen alergia a penicilina?"
- Pseudoanonimización → Cumplimiento HIPAA automático
- Gestión Documental → Expedientes organizados y accesibles al instante
- Digitaliza 50.000 expedientes en 2 meses vs 2 años manual
- 70% menos tiempo administrativo
- Cero riesgo de fuga de datos sensibles
Seguros
Documentos: Pólizas, formularios de reclamos, peritajes manuscritos, partes de siniestro, informes médicos de asegurados
Caso: Procesamiento automático de claims + extracción de partes manuscritos + detección de fraude
- OCR Manuscrito → Lee peritajes y partes escritos a mano
- Extracción Inteligente → Datos de pólizas y reclamos en segundos
- Modelo Detectar Riesgos → Identifica inconsistencias y posible fraude
- Modelo Comparar Documentos → Cruza información entre póliza y reclamo
- Chatbot Híbrido → "¿Qué reclamos superan €10.000 este mes?" (SQL + docs)
- Búsqueda Semántica → Encuentra casos similares anteriores
- Tiempo de respuesta: de 5 días a 4 horas
- 40% más detección de fraude
- 1.000 pólizas procesadas en minutos
¿Qué puede hacer MIKA por tu empresa?
Documentos Generales (Chatbot RAG)
Contratos, actas, informes, correspondencia, manuales, políticas internas
- Extraer información clave (fechas, partes, términos importantes)
- Auditar documentos para detectar incongruencias
- Comparar versiones y detectar cláusulas modificadas
- Resumir documentos largos en puntos clave
- Traducir a 80 idiomas instantáneamente
- Preguntar en lenguaje natural: "¿Qué contratos vencen este mes?"
Funcionalidades MIKA: Chatbot RAG • Modelos Auditar/Comparar/Resumir/Traducir • Búsqueda Semántica • 80 Idiomas
Documentos Estructurados (Extracción Inteligente)
Facturas, estados financieros, formularios, recibos, órdenes de compra, KYC
- Extraer datos automáticamente (montos, fechas, proveedores, líneas)
- Procesar en lote: sube un ZIP con miles de archivos
- Validar con indicador de confianza por campo
- Exportar a CSV, Excel o JSON
- Revisar y corregir errores con interfaz visual
Funcionalidades MIKA: Extracción Inteligente • Procesamiento Masivo • Plantillas Configurables • Validación Automática
Ahorros Reales en Clientes
Healthcare (Expedientes manuscritos)
Original:€2M, 24 meses, 15% errores
Con Mika:€200K, 2 meses, 98.5% precisión
Ahorro:90% costo • 92% tiempo • OCR manuscrito
Seguros (Procesamiento de claims)
Original:5 días por claim, 20% fraude no detectado
Con Mika:4 horas por claim, 40% más detección
Ahorro:95% tiempo • +40% detección fraude
Legal (Due Diligence M&A)
Original:6 abogados, 4 semanas, €200K
Con Mika:2 personas, 3 días, €5K
Ahorro:€195K + €3M en cláusulas renegociadas
Banca (Onboarding KYC)
Original:2 días por cliente, 12% errores
Con Mika:15 minutos por cliente, 0.5% errores
Ahorro:98% tiempo • 95% menos errores
Finanzas (Auditoría de contratos)
Original:5 personas, 3 semanas, €45K
Con Mika:1 persona, 2 días, €800
Ahorro:€176K/año (4 auditorías anuales)
Matriz Competitiva
Comparativa de MIKA vs principales competidores del mercado
| Capacidad | MIKA | ABBYY | Kofax | UiPath | Google DocAI |
|---|---|---|---|---|---|
| OCR | 98.5% | ||||
| OCR Manuscrito | |||||
| RAG / Chat | |||||
| Multi-LLM | |||||
| ML Tradicional | 20+ | ||||
| Big Data Native | |||||
| Spark/Databricks | |||||
| Pseudoanonimización | |||||
| 80 Idiomas | |||||
| Chat con SQL |
El Diferenciador de MIKA
MIKA es la única plataforma que integra IA generativa, machine learning tradicional y Big Data en una sola solución. Los competidores ofrecen piezas; nosotros ofrecemos el rompecabezas completo.
Único Multi-LLM
Orquestación de múltiples modelos de lenguaje. Ningún competidor ofrece esta flexibilidad.
Big Data Nativo
Integración real con Spark, Databricks y Kafka. Escala a millones de documentos.
20+ Algoritmos ML
El catálogo más completo de machine learning para análisis documental.