
Arquitectura 1: Pipeline distribuido con Ray para tolerancia a fallos
12/24/2025

Arquitectura 1: Pipeline distribuido con Ray para tolerancia a fallos
Por Walter Milstein
La Arquitectura 1 utiliza Ray para procesamiento distribuido con recursos GPU gestionados a 300 DPI. Este diseño prioriza tolerancia a fallos, observabilidad y escalabilidad multi-nodo sobre velocidad bruta en un solo nodo.
Justificación del diseño
Los despliegues empresariales requieren garantías de robustez: recuperación automática de fallos, monitoreo detallado y escalado horizontal. Ray proporciona estas capacidades a través de su modelo de actores, mecanismos de tolerancia a fallos y gestión de clusters.
Los archivos PDF ingresan a la arquitectura y se procesan a través de cinco etapas secuenciales dentro de la capa de orquestación distribuida de Ray: extracción convierte páginas PDF a imágenes, preprocesamiento mejora la calidad de imagen, OCR realiza reconocimiento de texto usando aceleración GPU, chunking segmenta el texto en bloques semánticos, y finalmente generación de embeddings con almacenamiento persiste los vectores en Weaviate.
Stack tecnológico
Orquestación: Ray 2.x para distribución, scheduling y tolerancia a fallos.
Motor OCR: PaddleOCR + TensorRT FP16 para inferencia acelerada por GPU.
Rasterización: Poppler (pdf2image) para conversión PDF a imagen.
Embeddings: OpenAI API (text-embedding-ada-002) para generación de vectores.
Base de datos vectorial: Weaviate para almacenamiento y búsqueda por similitud.
Estrategia de paralelización
La estrategia de paralelización se basa en el scheduler de Ray para particionar trabajo entre actores. Cada etapa del pipeline se ejecuta como actores Ray independientes con recursos explícitamente gestionados, permitiendo control fino sobre la asignación de CPU y GPU.
Ray asigna recursos GPU a los actores OCR explícitamente, previniendo contención y asegurando rendimiento predecible. La transferencia de datos inter-etapa aprovecha el object store de Ray, un mecanismo de memoria compartida que evita overhead repetido de serialización y deserialización al pasar arrays de imágenes grandes entre etapas.
Tolerancia a fallos
La Arquitectura 1 proporciona confiabilidad de grado empresarial mediante tres mecanismos:
Reintento automático: Las tareas fallidas se reprograman automáticamente a workers disponibles sin intervención manual.
Checkpointing: El progreso se guarda y puede reanudarse después de interrupciones del sistema.
Reinicio de actores: Los actores crasheados son automáticamente reiniciados por el supervisor de Ray, asegurando que el pipeline continúe procesando incluso cuando componentes individuales fallan.
Resultados experimentales
Los resultados revelan una arquitectura que exhibe comportamiento de escalado estable y predecible, con la capa de coordinación de Ray introduciendo overhead pero habilitando la robustez esperada de sistemas distribuidos de grado empresarial.
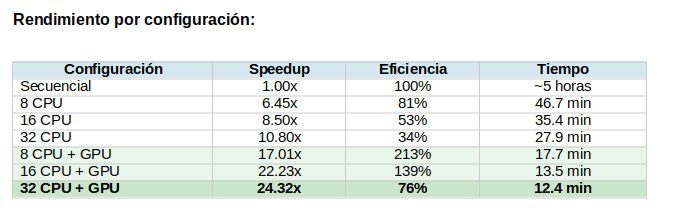
Análisis de resultados
A medida que aumentan los recursos CPU, el sistema muestra aceleración casi lineal en configuraciones solo-CPU, subiendo de 2.26x con 2 CPUs a 10.80x con 32 CPUs. Esto indica que el overhead de scheduling de Ray permanece controlado incluso bajo alta concurrencia de tareas.
Las configuraciones con GPU demuestran un efecto aún más pronunciado: una vez que se introduce la GPU, el cuello de botella se desplaza de la inferencia OCR a todas las etapas restantes del pipeline (rasterización PDF, preprocesamiento, chunking, embedding y almacenamiento). Como resultado, la mejora de throughput se vuelve dominada por el paralelismo del lado CPU mientras la GPU elimina el cuello de botella de inferencia.
Una observación clave es que la arquitectura mantiene escalado suave sin plateau temprano. Las configuraciones GPU escalan predeciblemente hasta 32 CPUs, sugiriendo que Ray balancea eficientemente el trabajo entre actores y que la contención GPU no se vuelve prohibitiva.
Throughput alcanzado
La configuración óptima—32 cores CPU con una GPU—logra 24.3x de speedup, reduciendo el tiempo total de procesamiento de aproximadamente 5 horas a solo 12.4 minutos, correspondiendo a un throughput de 917 páginas/minuto.
Ventajas y limitaciones
Ventajas
Robustez y observabilidad: El diseño proporciona tolerancia a fallos de grado empresarial adecuada para despliegues de misión crítica, mientras Ray Dashboard ofrece monitoreo en tiempo real del progreso de tareas, utilización de recursos y salud de la arquitectura.
Escalado horizontal: Agregar nodos al cluster Ray automáticamente aumenta la capacidad de procesamiento.
Alta calidad: El procesamiento a 300 DPI preserva detalles finos del documento para output OCR de alta calidad.
Limitaciones
Overhead de coordinación: La coordinación Ray introduce overhead de latencia comparado con procesamiento local, ya que las tareas deben ser scheduled, despachadas y los resultados agregados a través de la arquitectura distribuida.
Complejidad operacional: La arquitectura requiere setup y gestión continua del cluster Ray, aumentando la complejidad operacional.
Consumo de recursos: La infraestructura Ray consume recursos computacionales que de otro modo podrían dedicarse al procesamiento OCR.
¿Cuándo usar esta arquitectura?
La Arquitectura 1 es la opción recomendada cuando:
• Se requiere tolerancia a fallos para procesamiento de misión crítica.
• Se necesita monitoreo empresarial vía Ray Dashboard.
• La calidad máxima (300 DPI) es prioritaria sobre velocidad.
• Se requiere integración completa con pipeline RAG (chunking + embeddings + Weaviate).
• El despliegue es multi-nodo o se planea escalar horizontalmente.
Conclusión
La Arquitectura 1 demuestra que es posible lograr escalado predecible y garantías de robustez empresarial utilizando Ray como orquestador distribuido. Los resultados muestran que el diseño no persigue el tiempo mínimo absoluto, sino que entrega escalado predecible, resiliencia operacional y rendimiento competitivo incluso cuando procesa a alta resolución (300 DPI) con construcción completa de RAG.
En el próximo artículo, exploraremos la Arquitectura 2: el enfoque de máxima velocidad en un solo nodo que logra 69.9x de speedup eliminando todo overhead distribuido.
Próximo artículo: Arquitectura 2 - De 5 horas a 4 minutos: máxima velocidad local con ProcessPoolExecutor