

Transform unstructured documents into actionable data with conversational AI. Reduce up to 90% in costs and development time with our enterprise AI platform. A complete solution that democratizes access to advanced AI for all types of businesses.
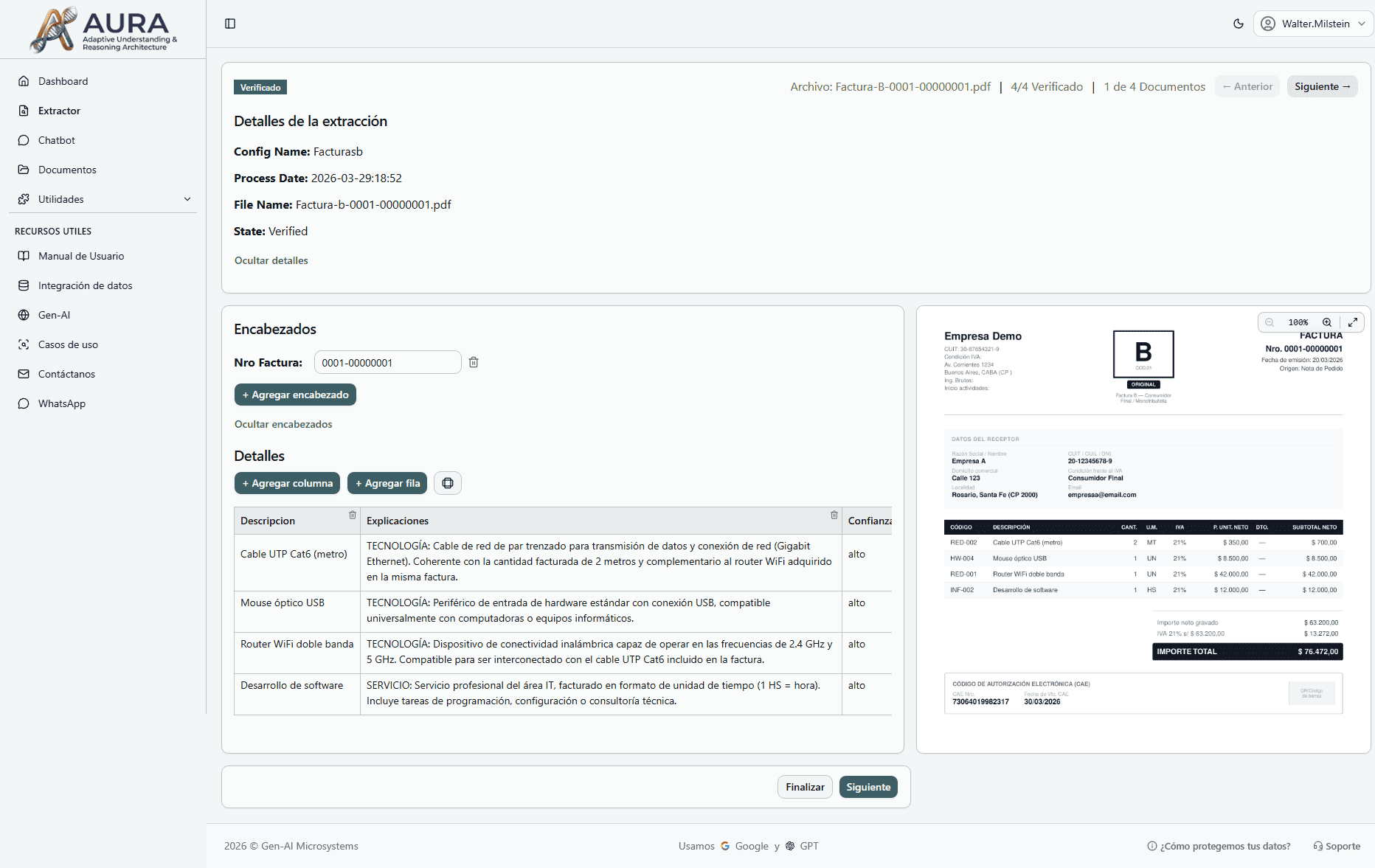
MIKA General Overview
The Market Problem
Companies have documents in silos, untapped data, and fragmented tools. Competitors offer partial solutions: some extract data, others do chat, others scale. No one integrates everything.
The MIKA Solution
MIKA is the only platform that combines three technological layers in one integrated solution:
Generative AI (LLMs)
To understand, converse and extract information from documents
Traditional ML
To predict, classify, detect anomalies and make decisions
Big Data
To scale to millions of documents with Spark, Databricks and Hadoop
El Diferenciador Único
From documents to decisions. Extract with generative AI, analyze with ML, scale with Big Data.
MIKA's Three Layers
LAYER 1: GENERATIVE AI
- •RAG / Chat
- •OCR Extraction
- •Summary
- •Translation
- •Q&A on docs
- •Generation
What does this contract say?
LAYER 2: TRADITIONAL ML
- •Automatic classification
- •Numerical prediction
- •Anomaly detection
- •Smart clustering
- •Time series
- •Interpretability
Is this document fraudulent?
LAYER 3: BIG DATA
- •Apache Spark
- •Databricks
- •Hadoop
- •Kafka
- •Delta Lake
- •Batch processing
Process 10M docs
Integrated Data Flow
The natural data flow in MIKA:
Layer 1: Generative AI (LLMs)
Power of advanced language models to understand, converse and extract information from documents
Core Capabilities
RAG (Retrieval)
Semantic search in documents. Ask in natural language and get contextual answers.
Document Chat
Converse with your files as if they were an expert. Ideal for contracts, manuals, policies.
Advanced OCR
Read handwritten text with 98.5% accuracy. No other system achieves this precision.
Data Extraction
Extract structured fields from invoices, contracts, forms automatically.
Multi-LLM
Orchestration of Claude, GPT, Gemini, Llama. Use the best model for each task.
80 Languages
Process documents in any language without additional configuration.
Pseudo-anonymization
Protect sensitive data before sending to external LLMs. Compliance from day one.
SQL Chat
Ask "how many invoices over €10K?" and MIKA generates the query automatically.
Multi-LLM: The Best of Each Model
MIKA automatically orchestrates multiple language models (Claude, GPT-4, Gemini, Llama) choosing the most suitable for each task. You get the best result without worrying about technical complexity.
Layer 2: Traditional Machine Learning
Why Traditional ML when you have LLMs?
LLMs are excellent for understanding and generating text, but traditional models are superior for:
Numerical prediction
Risk scoring, default probability, churn
Fast classification
Document type in milliseconds, not seconds
Anomaly detection
Fraud, altered documents, outlier values
Interpretability
Explain why a contract is risky (required by regulators)
Cost
100x cheaper inference than LLMs for repetitive tasks
Available Models Catalog
Random Forest
What is:
Ensemble of decision trees that vote by majority. Robust and precise.
Key Parameters:
n_estimators (100-500), max_depth (10-30), min_samples_split
MIKA Case:
Classify document type (invoice, contract, policy) with 95%+ accuracy.
Advantage:
Interpretable (feature importance), handles missing data
XGBoost
What is:
Optimized gradient boosting. The gold standard in Kaggle competitions.
Key Parameters:
learning_rate (0.01-0.3), max_depth (3-10), n_estimators, subsample
MIKA Case:
Contract risk scoring. Litigation probability.
Advantage:
Maximum precision, handles class imbalance, GPU support
LightGBM
What is:
Microsoft gradient boosting. Faster than XGBoost on large datasets.
Key Parameters:
num_leaves, learning_rate, feature_fraction, bagging_fraction
MIKA Case:
Mass classification of millions of documents in batch.
Advantage:
10x faster than XGBoost, lower memory consumption
20+ ML Algorithms at Your Fingertips
MIKA includes more than 20 machine learning algorithms ready to use in your documents. From simple classification to advanced neural networks, everything integrated in one platform.
Layer 3: Big Data & Scale
Native integration with the main Big Data platforms on the market
Big Data Integrations
Apache Spark
Capacidad:
In-memory distributed processing. Up to 100x faster than MapReduce.
Caso de Uso:
Process 10M+ invoices in hours. Massive extraction. Document ETL.
Databricks
Capacidad:
Unified Lakehouse. Analytics + ML + BI in one platform.
Caso de Uso:
Complete pipeline: ingest docs → extract → analyze → dashboards.
Hadoop HDFS
Capacidad:
Distributed storage. Petabytes of data.
Caso de Uso:
Historical document archive. Document data lake.
Apache Kafka
Capacidad:
Real-time streaming. Events and messaging.
Caso de Uso:
Process documents instantly. Real-time fraud alerts.
Delta Lake
Capacidad:
ACID over data lakes. Versioning and time travel.
Caso de Uso:
Document auditing. Rollback. Historical compliance.
Apache Hive
Capacidad:
SQL over Hadoop. Data warehouse.
Caso de Uso:
Analytical queries on millions of processed documents.
Apache Airflow
Capacidad:
Workflow orchestration. Programmatic DAGs.
Caso de Uso:
Automate document processing pipelines.
Presto/Trino
Capacidad:
Federated SQL queries. Multi-source.
Caso de Uso:
Unified query on docs in S3, Hadoop, databases.
Scale Scenarios
MIKA adapts to any document processing volume, from small businesses to global corporations
SMB
Volumen
10K docs/month
Stack
MIKA Core
Tiempo
Seconds
Enterprise
Volumen
1M docs/month
Stack
MIKA + Spark
Tiempo
Hours
Mega Corp
Volumen
100M+ docs/month
Stack
MIKA + Databricks
Tiempo
Nightly batch
Real Time
Volumen
Streaming
Stack
MIKA + Kafka
Tiempo
Milliseconds
Limitless Scalability
MIKA grows with you. Start processing thousands of documents per month and scale to hundreds of millions without changing platforms. One architecture, infinite possibilities.
The problem Mika solves
Without Mika
- Your teams lose 8+ hours a week searching for information in documents
- Auditing 100 contracts requires 6 people and 4 weeks
- You can't use ChatGPT with sensitive data: risk of data breaches and GDPR fines
- Handwritten documents are processed manually, with a 15-20% error rate
- Information is siloed: nobody can find what they need
With Mika
- Semantic search: find any document in seconds
- Audit 100 contracts in 10 minutes with one person
- Automatic pseudo-anonymization: use AI without compliance risk
- 98.5% accuracy for handwritten OCR
- Everything connected: Drive, SharePoint, databases, all in one place
Result with Mika: 90% less time • 95% fewer errors • 100% compliance
Explore Mika in action
Navigate through all the platform's features
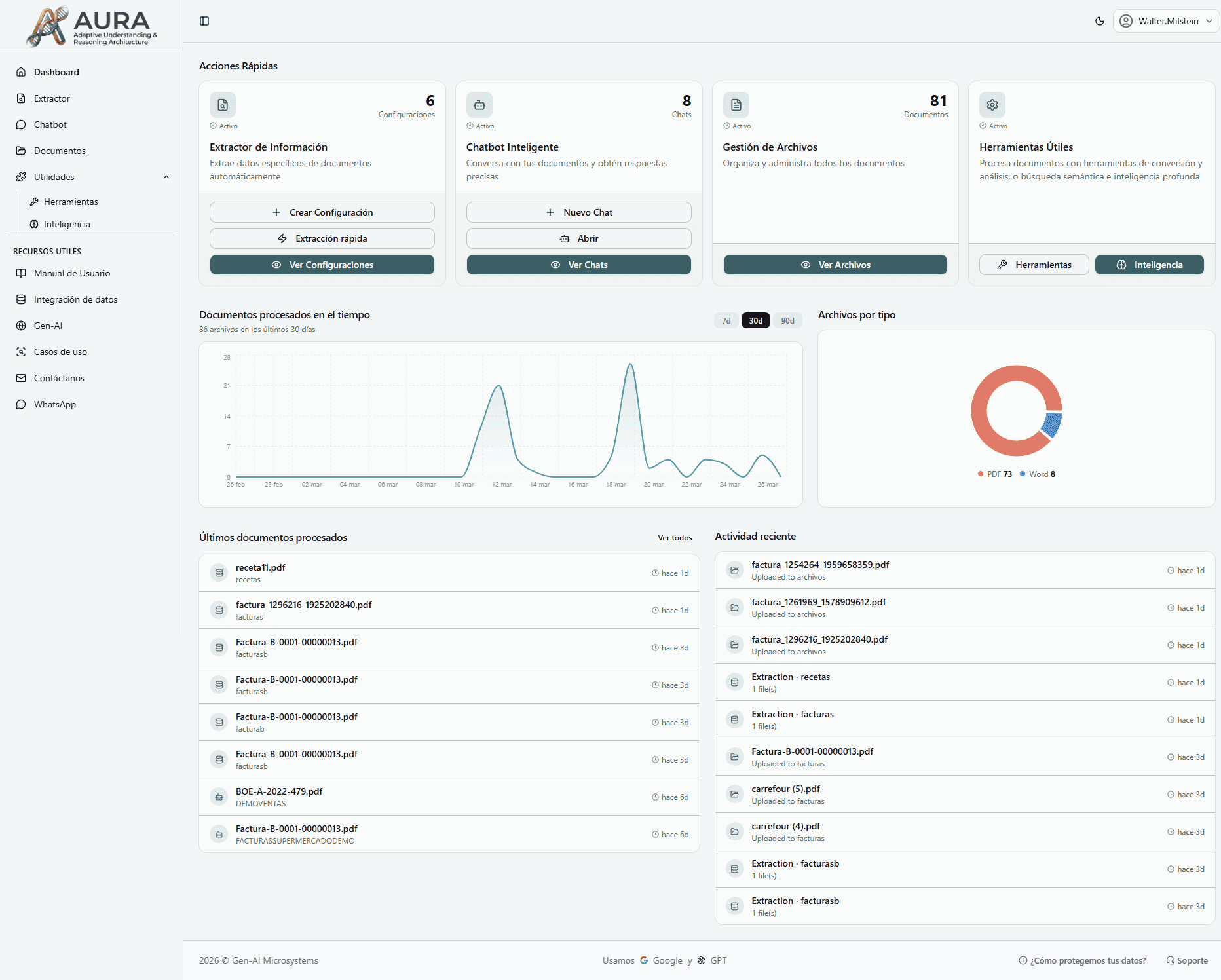
How to Use Mika
Automate document processing in just a few steps
Create Your Custom Configuration
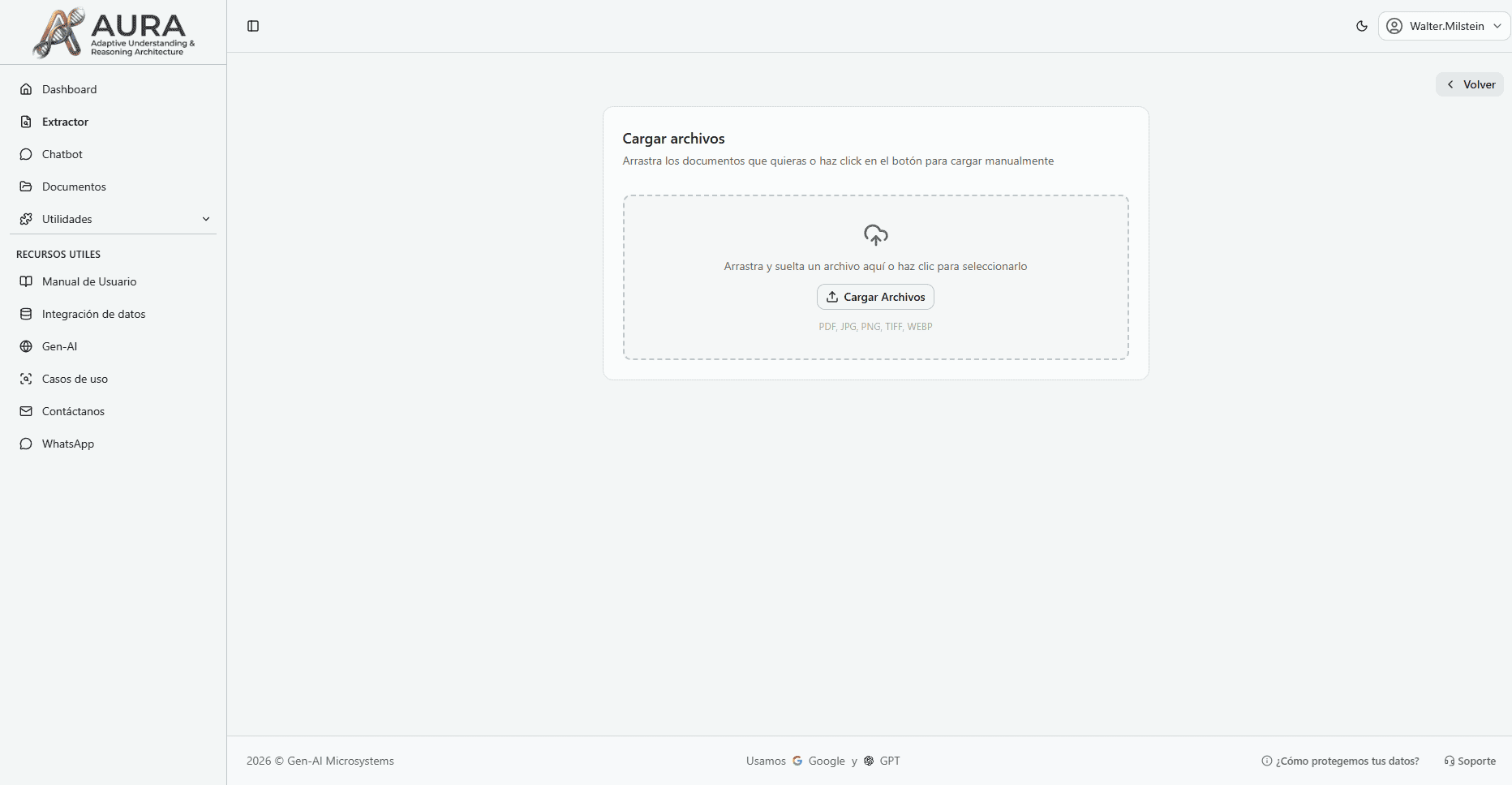
- 1Upload a sample document with the format you want to process.
- 2Select the key fields you want to extract (such as amount, date, or supplier).
- 3Train and save the configuration with a descriptive name to reuse it anytime.
Run Mass Extraction
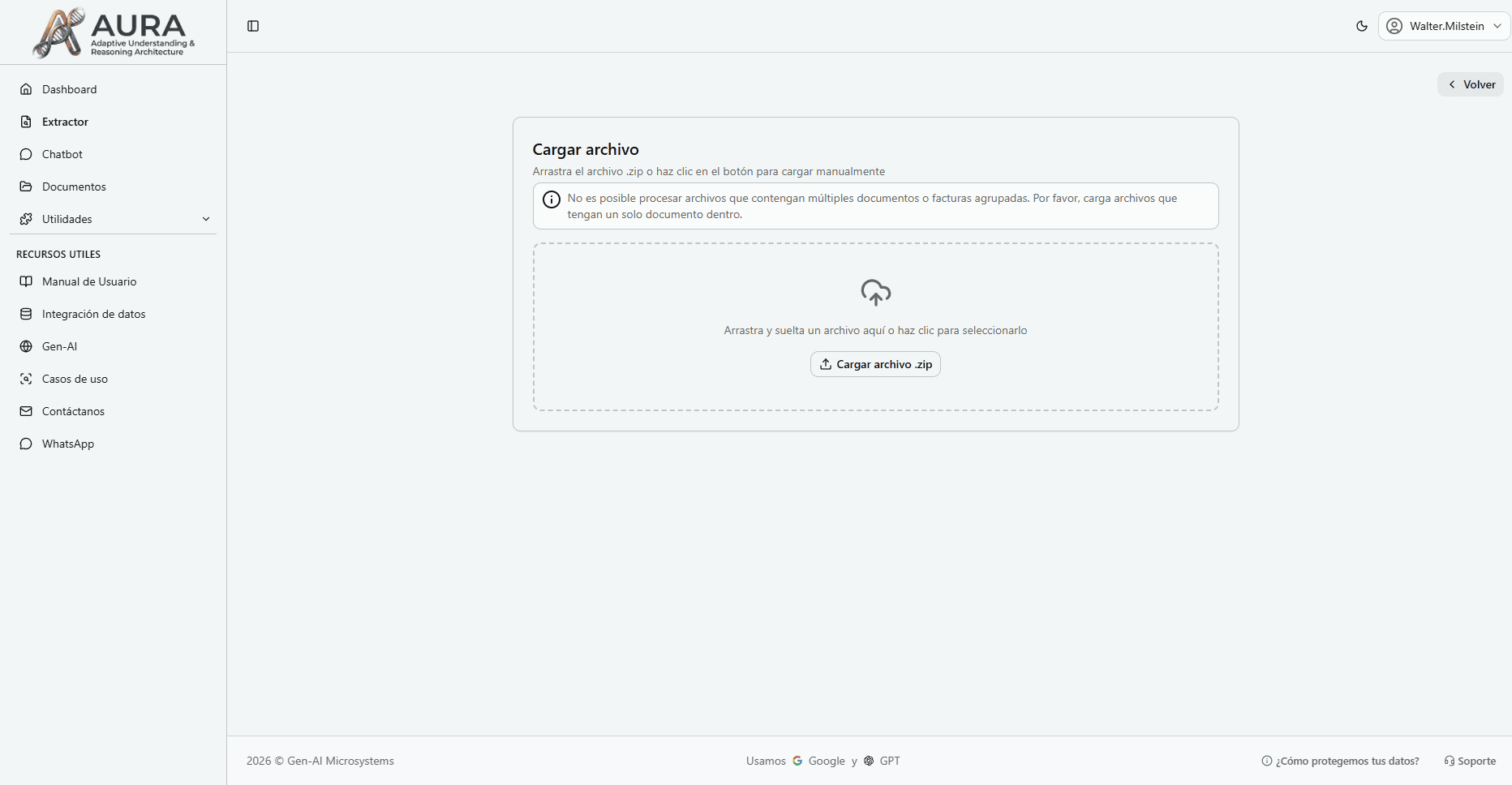
- 1Select the saved configuration.
- 2Upload a ZIP file containing multiple documents of the same type.
- 3Click 'Run' and let Mika process all files automatically.
Review and Download Results
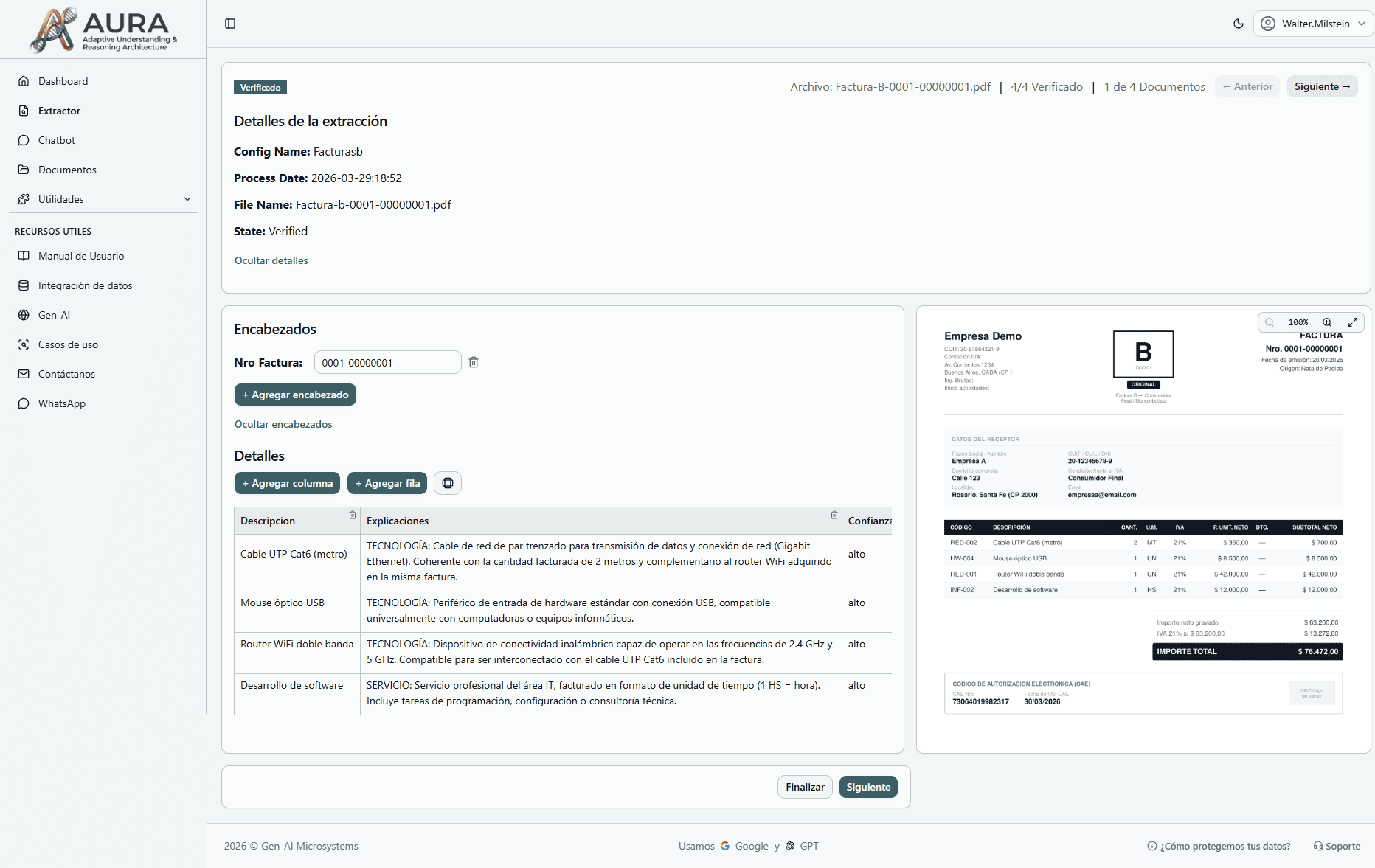
- 1Once the process is complete, access the results from the corresponding section.
- 2Manually review and correct any data if necessary.
- 3Download the extracted data in CSV, Excel, or JSON format to use in other systems.
How to use the chatbot
Configure, train and start interacting in minutes
Create and train your chat
- 1Upload one or more documents related to the chat's topic.
- 2Select the document type in configuration: Common (legal, letters, minutes) or Structured (accounting, forms, financial reports).
- 3Name your chat descriptively and save it for later use.
Interact with your chat
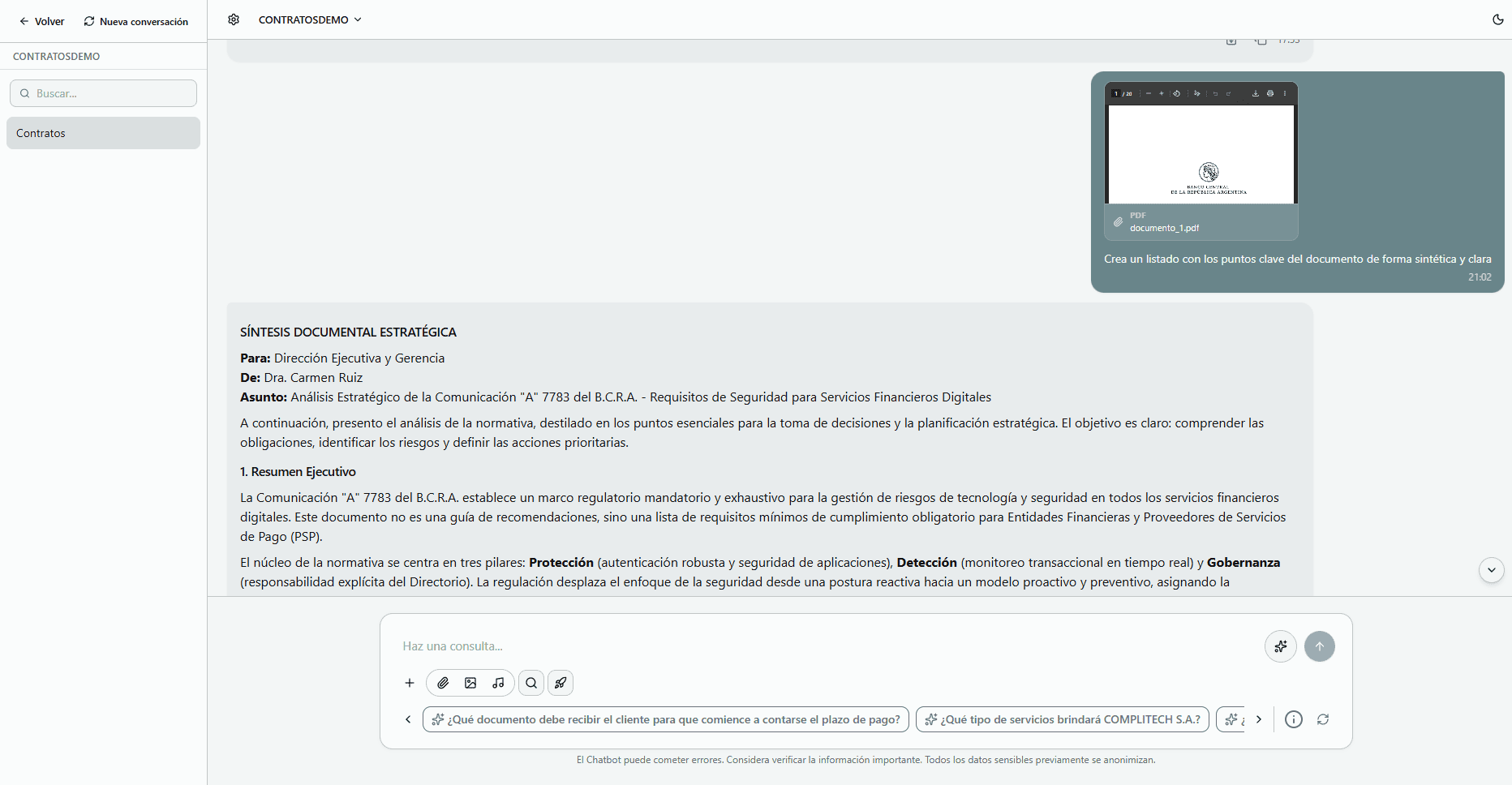
- 1Enter the chat from the list of saved ones.
- 2Ask questions about the uploaded documents using natural language.
- 3Request specific actions like summaries, translations, or comparisons.
- 4Interact with PDF documents, images and audio files.
Use AI-Generated Suggested Questions
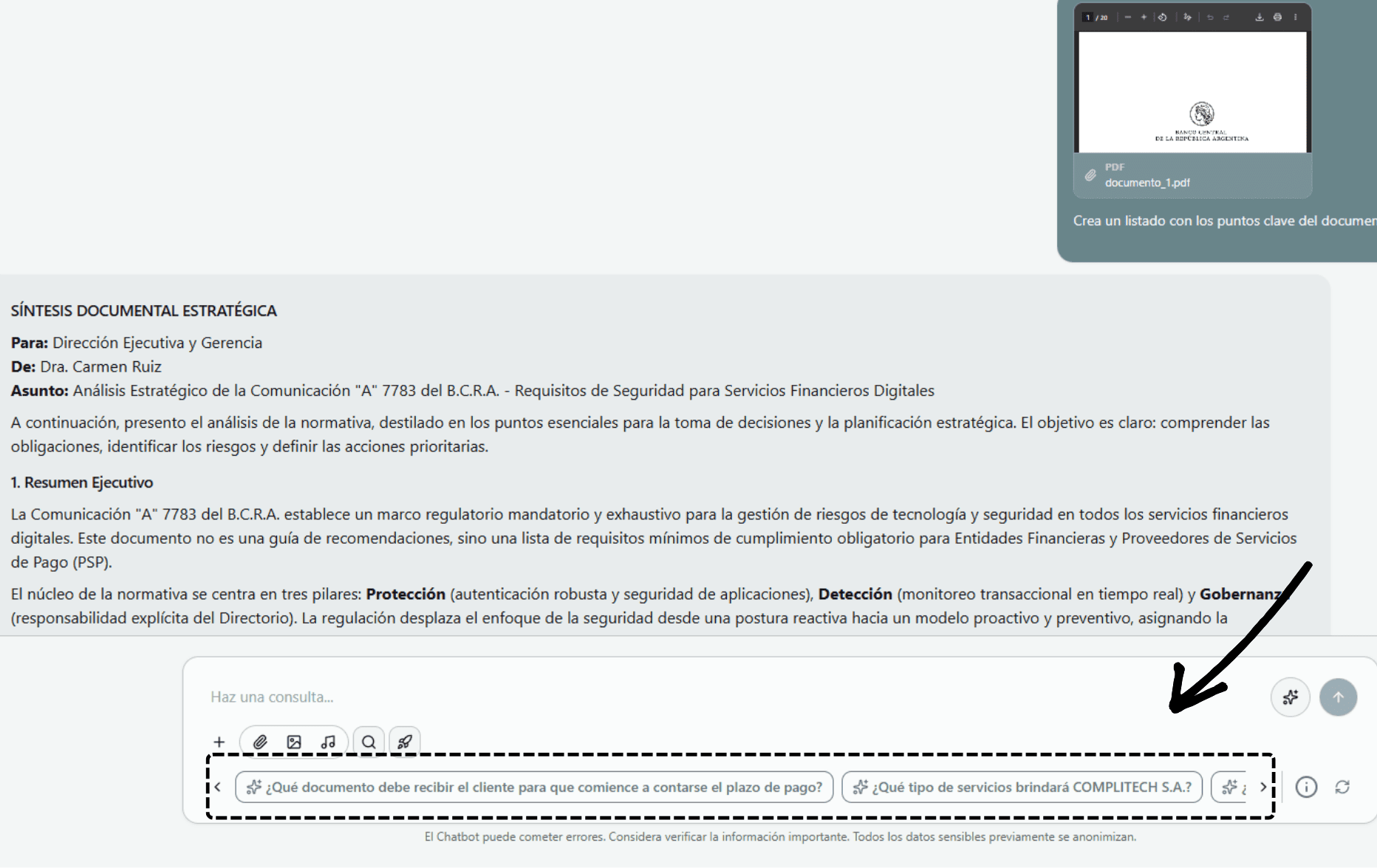
- 1When opening a chat, Mika analyzes the uploaded documents and automatically generates relevant questions.
- 2Click any suggested question to start the conversation without typing anything.
- 3Suggestions update based on the conversation context and available documents.
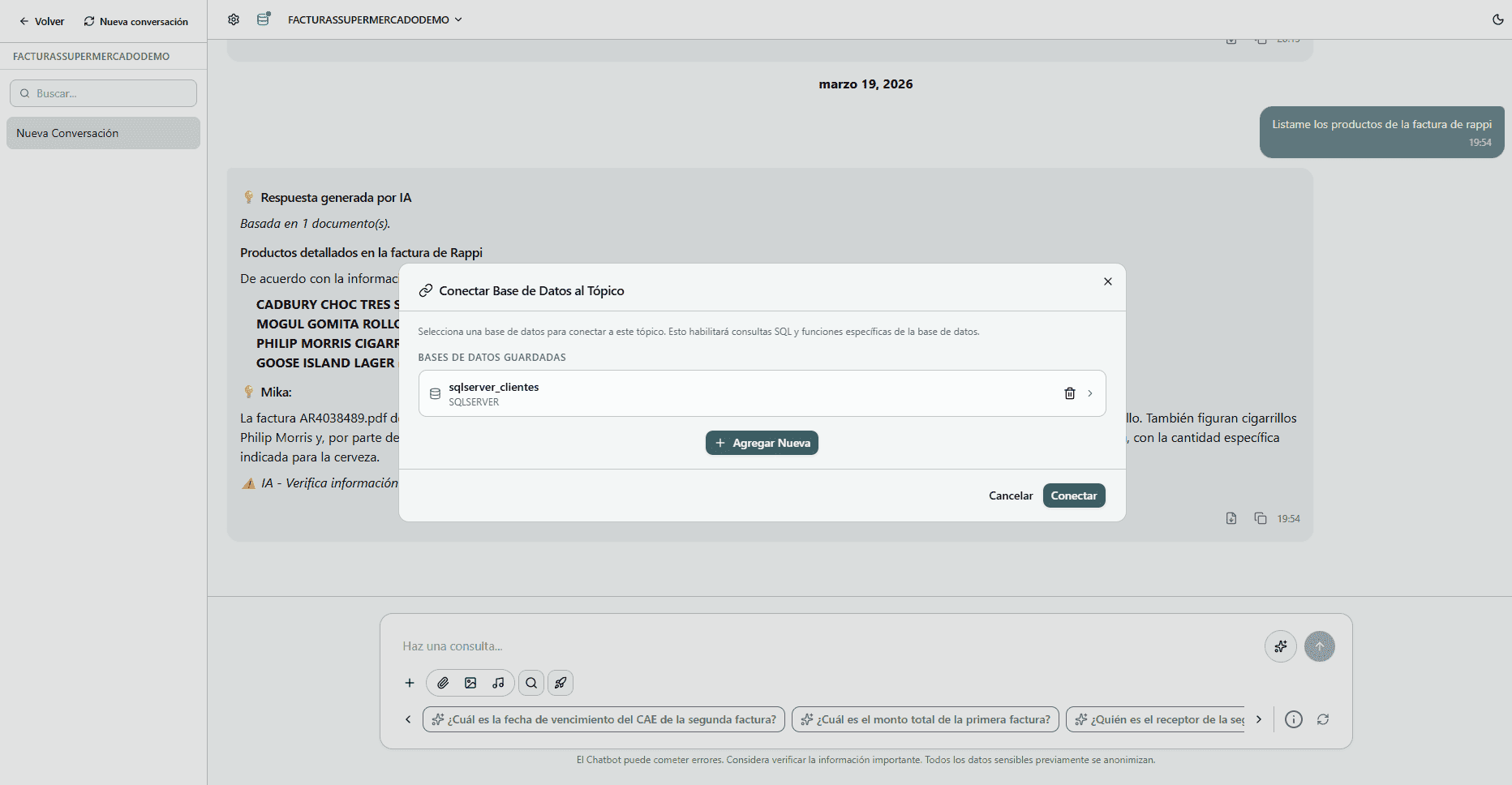
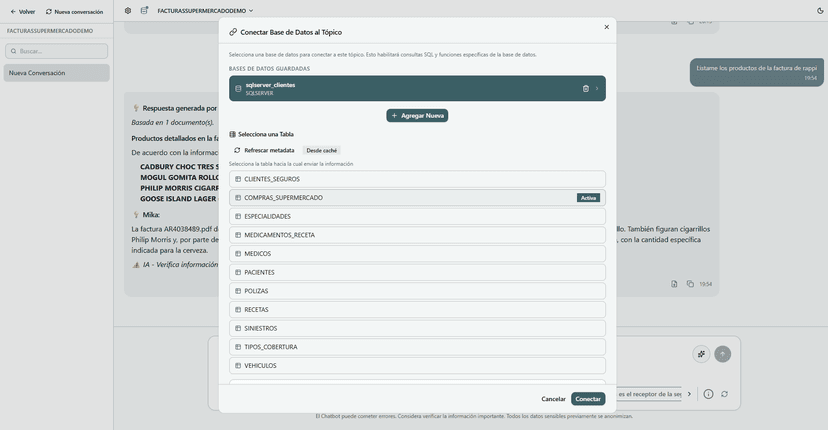
Connect Mika to your databases
Mika integrates natively with your relational and non-relational databases, unlocking a new level of intelligence over your own structured data.
- Chat over your data — Query tables, reports, and metrics in natural language — no SQL knowledge needed.
- Extractions to your DB — Automatically save data extracted from documents directly into your tables.
- Enriched context — Combine documents and structured data in a single chat for more complete answers.
- Ready-made connectors — Compatible with PostgreSQL, MySQL, SQL Server, MongoDB and more, with no extra development.
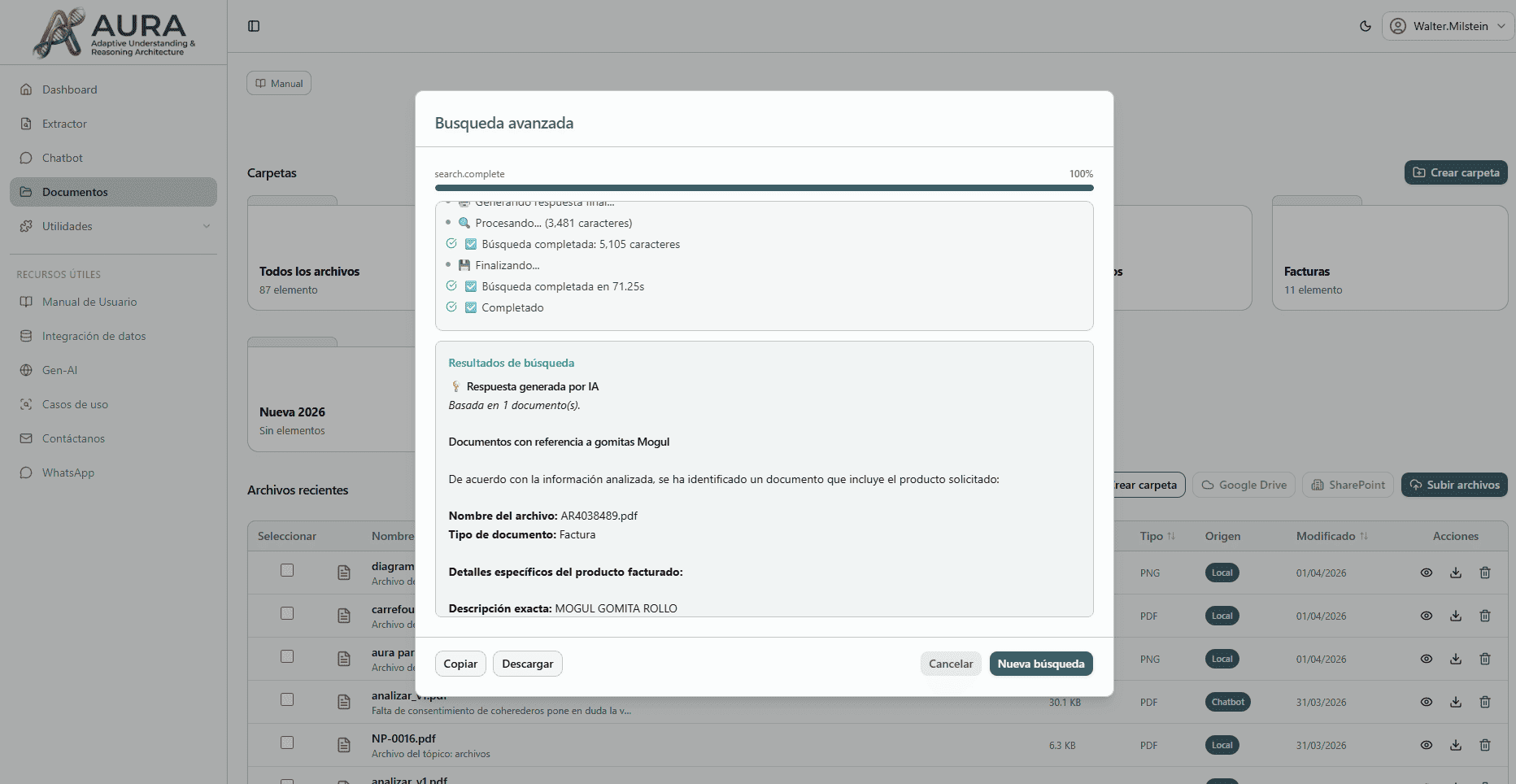
Find any document just by describing it
Forget folders and filters. With Mika you can write what you need in natural language and the AI locates the exact document among thousands in seconds.
- Natural language — Write the way you talk: 'Juan's contract from last year' and Mika finds it.
- Semantic search — It doesn't match keywords — it understands the meaning and context of your query.
- Automatic filters — Mika detects dates, document types, and people from your prompt with no manual setup.
- Instant results — Ranks and presents the most relevant documents with a summary of why they match.

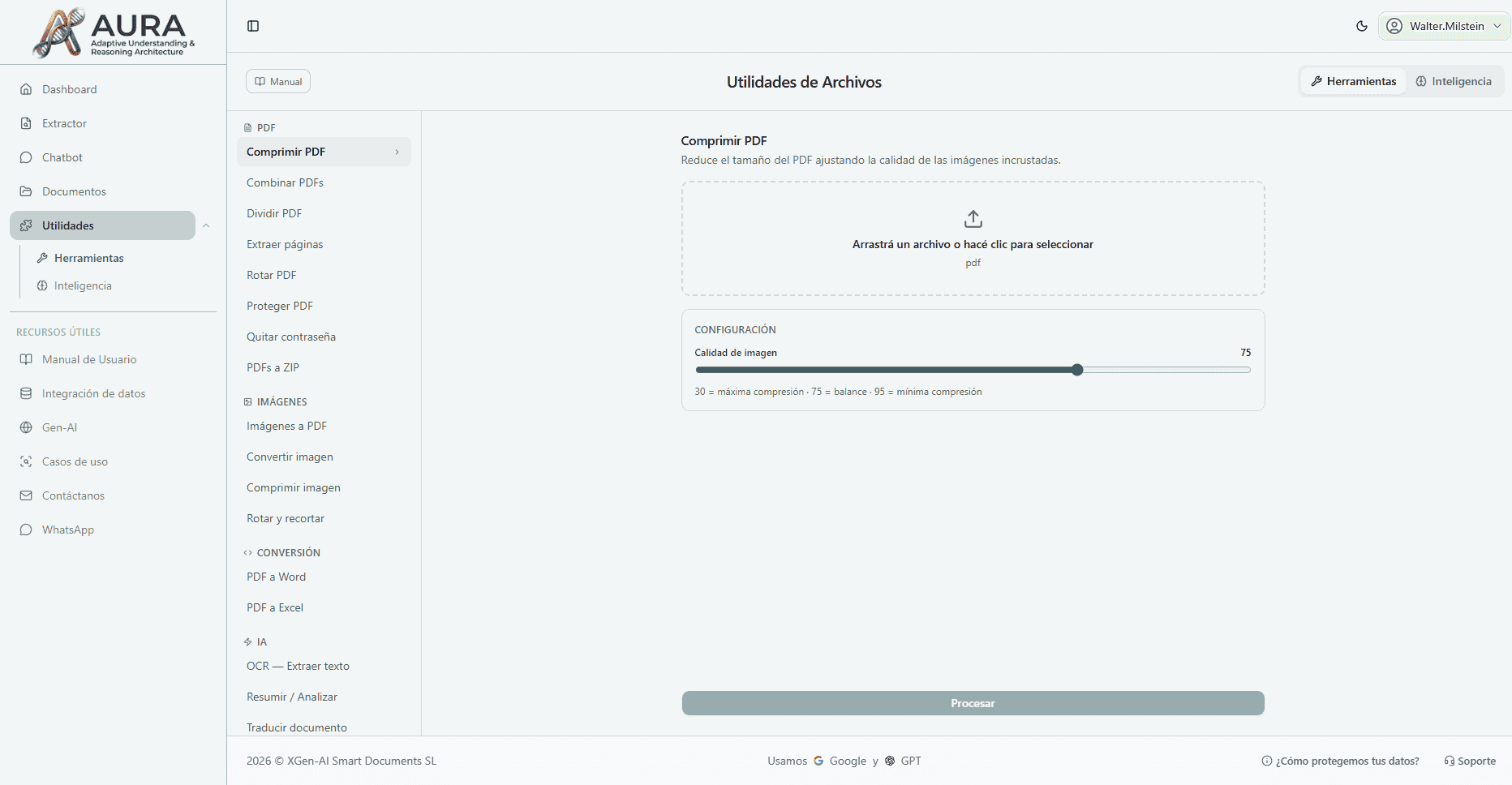
Tools for every task
Mika utilities are split into two major blocks: Tools, with 17 utilities to manipulate PDFs, images, text and perform conversions; and Intelligence, with semantic search and advanced reasoning capabilities over documents.
What does Mika do?
Intelligent Extraction
Configure custom templates to extract specific information from your documents with 98.5% accuracy
Document Management
Organize, classify and manage all your documents in a centralized and intelligent system
Conversational AI
Interact with your documents using natural language. Ask, analyze and get instant answers
Administrative Dashboard
Monitor performance, manage users and get detailed insights on document processing
Advanced Search
Find specific information in thousands of documents using AI-powered semantic search
Mass Processing
Process hundreds of documents simultaneously with automatic extraction and result validation
More than 80 languages and dialects supported
Mika processes, extracts and converses in hundreds of languages and regional variants from around the world.
+164
languages and dialects
Industry Use Cases
MIKA-specific solutions adapted to each sector's needs
Healthcare / Pharma
Clinical records
MIKA Solution:
Medical handwritten OCR + diagnosis extraction + HIPAA pseudo-anonymization
Models:
Readmission prediction
MIKA Solution:
Analyze patient history and predict 30-day readmission probability
Models:
Pharmacovigilance
MIKA Solution:
Process adverse effect reports + pattern clustering + alerts
Models:
Clinical trials
MIKA Solution:
Extract data from 10K+ trial documents + efficacy analysis
Models:
Your Industry Not Listed Here?
MIKA is fully customizable for any sector. Contact us to design a specific solution for your industry and use cases.
Technical Architecture
A robust and scalable architecture designed for enterprise-level document processing
Architecture Diagram
INPUT LAYER
MIKA CORE
MIKA LLM
MIKA ML
MIKA BIG DATA
OUTPUT LAYER
| Layer | Technology |
|---|---|
| Backend | PythonFastAPICeleryRedisPostgreSQLElasticsearch |
| LLMs | Claude APIOpenAI APIGeminiLlama (self-hosted)LangChain |
| ML | Scikit-learnXGBoostLightGBMPyTorchTensorFlowMLflow |
| Big Data | Apache SparkDatabricksHadoopKafkaDelta LakeAirflow |
| Infra | KubernetesDockerAWS/Azure/GCPTerraformPrometheusGrafana |
| Frontend | ReactTypeScriptTailwindCSSChart.jsAG Grid |
Enterprise-Class Architecture
MIKA uses the best technologies on the market in each layer. A modular, scalable architecture proven in production by companies worldwide.
Use Cases
Healthcare
Documents: Handwritten clinical histories, handwritten prescriptions, nursing notes, laboratory reports, diagnostic images (X-rays, MRIs, ultrasounds)
Case: Digitization of handwritten records + automatic structuring of histories + medical image analysis
- Handwritten OCR → Reads prescriptions and medical notes with 98.5% accuracy
- Intelligent Extraction → Automatically structures laboratory data
- Image Analysis → Assisted diagnosis on radiological plates
- RAG Chatbot → "Which patients are allergic to penicillin?"
- Pseudo-anonymization → Automatic HIPAA compliance
- Document Management → Records organized and instantly accessible
- Digitizes 50,000 records in 2 months vs 2 years manual
- 70% less administrative time
- Zero risk of sensitive data leakage
Insurance
Documents: Policies, claim forms, handwritten appraisals, accident reports, insured medical reports
Case: Automatic claims processing + handwritten parts extraction + fraud detection
- Handwritten OCR → Reads handwritten appraisals and reports
- Intelligent Extraction → Policy and claim data in seconds
- Risk Detection Model → Identifies inconsistencies and possible fraud
- Document Comparison Model → Cross-references information between policy and claim
- Hybrid Chatbot → "Which claims exceed €10,000 this month?" (SQL + docs)
- Semantic Search → Finds similar previous cases
- Response time: from 5 days to 4 hours
- 40% more fraud detection
- 1,000 policies processed in minutes
What can MIKA do for your company?
General Documents (RAG Chatbot)
Contracts, minutes, reports, correspondence, manuals, internal policies
- Extract key information (dates, parties, important terms)
- Audit documents to detect inconsistencies
- Compare versions and detect modified clauses
- Summarize long documents into key points
- Translate to 80 languages instantly
- Ask in natural language: "Which contracts expire this month?"
MIKA Features: RAG Chatbot • Audit/Compare/Summarize/Translate Models • Semantic Search • 80 Languages
Structured Documents (Smart Extraction)
Invoices, financial statements, forms, receipts, purchase orders, KYC
- Automatically extract data (amounts, dates, suppliers, lines)
- Batch processing: upload a ZIP with thousands of files
- Validate with confidence indicator per field
- Export to CSV, Excel or JSON
- Review and correct errors with visual interface
MIKA Features: Smart Extraction • Mass Processing • Configurable Templates • Automatic Validation
Real Savings in Clients
Healthcare (Handwritten Records)
Original:€2M, 24 months, 15% errors
With Mika:€200K, 2 months, 98.5% accuracy
Savings:90% cost • 92% time • Handwritten OCR
Insurance (Claims Processing)
Original:5 days per claim, 20% undetected fraud
With Mika:4 hours per claim, 40% more detection
Savings:95% time • +40% fraud detection
Legal (M&A Due Diligence)
Original:6 lawyers, 4 weeks, €200K
With Mika:2 people, 3 days, €5K
Savings:€195K + €3M in renegotiated clauses
Banking (KYC Onboarding)
Original:2 days per client, 12% errors
With Mika:15 minutes per client, 0.5% errors
Savings:98% time • 95% fewer errors
Finance (Contract Auditing)
Original:5 people, 3 weeks, €45K
With Mika:1 person, 2 days, €800
Savings:€176K/year (4 annual audits)
Competitive Matrix
MIKA vs main market competitors comparison
| Capability | MIKA | ABBYY | Kofax | UiPath | Google DocAI |
|---|---|---|---|---|---|
| OCR | 98.5% | ||||
| OCR Manuscrito | |||||
| RAG / Chat | |||||
| Multi-LLM | |||||
| ML Tradicional | 20+ | ||||
| Big Data Native | |||||
| Spark/Databricks | |||||
| Pseudoanonimización | |||||
| 80 Idiomas | |||||
| Chat con SQL |
MIKA's Differentiator
MIKA is the only platform that integrates generative AI, traditional machine learning and Big Data in one solution. Competitors offer pieces; we offer the complete puzzle.
Unique Multi-LLM
Orchestration of multiple language models. No competitor offers this flexibility.
Native Big Data
Real integration with Spark, Databricks and Kafka. Scales to millions of documents.
20+ ML Algorithms
The most complete machine learning catalog for document analysis.