
Arquitectura 2: De 5 horas a 4 minutos con ProcessPoolExecutor
12/23/2025

Arquitectura 2: De 5 horas a 4 minutos con ProcessPoolExecutor
Por Walter Milstein
La Arquitectura 2 maximiza el throughput en un solo nodo utilizando ProcessPoolExecutor nativo de Python para paralelismo CPU con acceso directo a GPU a 100 DPI. Este diseño elimina por completo el overhead de computación distribuida.
Justificación del diseño
El insight clave es que el procesamiento de documentos es embarazosamente paralelo a nivel de archivo—cada PDF puede procesarse independientemente. Al usar paralelismo a nivel de proceso del sistema operativo en lugar de frameworks distribuidos, la Arquitectura 2 evita overhead de serialización, latencia de red y complejidad de coordinación.
El uso de 100 DPI reduce el volumen de datos en 9x comparado con 300 DPI, con recuperación de calidad mediante post-procesamiento de reconstrucción.
Stack tecnológico
Paralelización: ProcessPoolExecutor (librería estándar de Python) para paralelismo a nivel de proceso del SO.
Acceso a PDF: PyMuPDF (fitz) para extracción zero-copy de pixmap.
Preprocesamiento: OpenCV para CLAHE y binarización Otsu.
Motor OCR: PaddleOCR para detección y reconocimiento de texto.
Post-procesamiento: Fuzzy matching para reconstrucción de texto.
Diferencias clave con Arquitectura 1
El stack tecnológico difiere significativamente de la Arquitectura 1:
Sin Ray: ProcessPoolExecutor de la librería estándar de Python proporciona paralelismo a nivel de SO sin dependencias externas.
PyMuPDF en lugar de Poppler: Acceso zero-copy a PDF para máxima velocidad, eliminando el cuello de botella de rasterización que representa 22% del tiempo en pipelines tradicionales.
100 DPI en lugar de 300 DPI: Reducción de 9x en volumen de datos, compensada con reconstrucción fuzzy.
Pipeline RAG opcional: Enfocado en extracción OCR pura; chunking y embeddings pueden agregarse según necesidad.
Estrategia de paralelización
Los archivos PDF se distribuyen a través de múltiples procesos worker, cada uno ejecutando el pipeline de procesamiento completo independientemente. A diferencia de la Arquitectura 1 donde Ray orquesta etapas individuales, aquí cada worker maneja extracción, preprocesamiento, OCR y post-procesamiento como una unidad única.
Los archivos PDF se particionan en batches y asignan a procesos worker al inicio. El conteo de procesos es configurable, típicamente coincidiendo con el conteo de cores CPU—configuraciones de 16 a 32 workers son comunes. Todos los procesos comparten acceso a una sola GPU para inferencia OCR, con el sistema operativo gestionando el scheduling de GPU.
Los workers ejecutan independientemente sin comunicación inter-proceso—una vez asignado un batch, cada worker procesa sus archivos sin coordinación, recolectando resultados solo al completarse.
Resultados experimentales
Los resultados revelan una arquitectura optimizada para rendimiento bruto, donde la ausencia de overhead de coordinación distribuida se traduce directamente en velocidad de procesamiento.
Rendimiento por configuración:
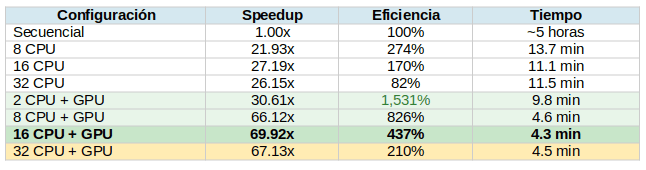
El fenómeno del speedup super-lineal
La configuración 2 CPU + GPU logra una eficiencia extraordinaria de 1,531%—un speedup super-lineal que parece contradecir los límites teóricos. Este fenómeno se atribuye a múltiples factores:
Mejoras de localidad de caché: Procesar datos en loops cerrados mantiene datos calientes en caché L1/L2.
GPU latency masking: Workers CPU preparan el siguiente batch mientras la GPU procesa el actual.
Eliminación completa de serialización: Sin overhead de frameworks distribuidos.
Este speedup super-lineal persiste en 4 CPU + GPU (1,236%) y 8 CPU + GPU (826%) antes de normalizarse en conteos de workers más altos donde los efectos de contención dominan.
El sweet spot: 16 CPUs + GPU
A diferencia de la Arquitectura 1 que mantiene escalado suave hasta 32 CPUs, la Arquitectura 2 exhibe un claro plateau de rendimiento seguido de degradación:
16 CPU + GPU: 69.92x speedup (óptimo)
32 CPU + GPU: 67.13x speedup (degradación)
Este comportamiento ocurre porque múltiples procesos compitiendo por una sola GPU compartida crean contención que serializa lo que debería ser ejecución paralela. La configuración de 16 CPUs representa el "sweet spot" donde el paralelismo CPU se maximiza sin abrumar la capacidad de scheduling de la GPU.
Implicación práctica: Los profesionales que despliegan la Arquitectura 2 deben ajustar cuidadosamente el conteo de workers en lugar de simplemente maximizar la utilización de CPU.
Throughput alcanzado
La configuración óptima—16 cores CPU con una GPU—logra 69.92x de speedup, reduciendo el tiempo total de procesamiento de aproximadamente 5 horas a solo 4.3 minutos, correspondiendo a un throughput de 2,644 páginas/minuto.
Esto representa casi 3x el throughput de la configuración óptima de la Arquitectura 1.
Ventajas y limitaciones
Ventajas
Simplicidad: La arquitectura completa se ejecuta como un script Python standalone sin dependencias de infraestructura, haciendo el despliegue directo en cualquier máquina con Python y GPU.
Velocidad máxima: Al eliminar overhead de computación distribuida y usar 100 DPI (9x menos datos que 300 DPI), esta arquitectura logra el throughput más alto en un solo nodo.
Cero costos de API: No se requieren servicios cloud ni costos de API para el pipeline OCR core.
Limitaciones
Escalabilidad limitada: Limitada por hardware de un solo nodo—no hay mecanismo para distribuir trabajo entre múltiples máquinas.
Sin recuperación automática: Los fallos de proceso pierden el batch asignado sin recuperación automática, requiriendo reinicio manual.
Contención GPU: Múltiples procesos compitiendo por acceso GPU pueden crear contención, reduciendo eficiencia más allá de ciertos conteos de workers.
Menor resolución: La resolución de 100 DPI requiere reconstrucción post-procesamiento para recuperar calidad de texto aceptable.
¿Cuándo usar esta arquitectura?
La Arquitectura 2 es la opción recomendada cuando:
• La velocidad de procesamiento es la prioridad máxima.
• El despliegue debe ser simple, sin infraestructura distribuida.
• El hardware es confiable y los fallos transitorios son infrecuentes.
• La carga de trabajo cabe dentro de la capacidad de un solo nodo.
• La calidad de OCR "suficientemente buena" (con reconstrucción) es aceptable.
• Se desea evitar costos y complejidad de servicios cloud.
Comparación directa con Arquitectura 1

Conclusión
La Arquitectura 2 demuestra que el procesamiento OCR masivo no requiere frameworks distribuidos complejos. Al eliminar overhead de coordinación y optimizar el acceso a datos, logra casi 3x el throughput de la Arquitectura 1 con una fracción de la complejidad.
El trade-off es explícito: sin tolerancia a fallos, sin escalado horizontal, y un "performance cliff" más allá del sweet spot. Esto posiciona a la Arquitectura 2 como la opción más apropiada para escenarios donde la velocidad de procesamiento es primordial, el hardware es confiable, y la carga de trabajo cabe dentro de la capacidad de un solo nodo.
En el próximo artículo, exploraremos la Arquitectura 3: el diseño híbrido que combina la orquestación de Ray con la velocidad de procesamiento local de la Arquitectura 2.
Próximo artículo: Arquitectura 3 - Diseño híbrido: escalando horizontalmente con el patrón Pure Dispatcher