
Arquitectura 3: Diseño híbrido con el patrón Pure Dispatcher
12/23/2025

Arquitectura 3: Diseño híbrido con el patrón Pure Dispatcher
Por Walter Milstein
La Arquitectura 3 representa la principal novedad de esta investigación: un diseño híbrido basado en el patrón Pure Dispatcher. Este patrón permite que Ray actúe exclusivamente como coordinador stateless—particionando el corpus por conteo de páginas y distribuyendo batches balanceados a través de múltiples nodos—mientras cada nodo ejecuta el pipeline local optimizado de la Arquitectura 2 con su propia GPU dedicada.
Esta separación de responsabilidades logra speedup casi-lineal: distribuir trabajo entre N GPUs reduce el tiempo de procesamiento aproximadamente N veces, combinando escalabilidad distribuida con eficiencia de procesamiento local.
Justificación del diseño
El insight clave es la separación de responsabilidades: Ray maneja únicamente orquestación (particionamiento, despacho, agregación) mientras el procesamiento real utiliza el pipeline local probado de la Arquitectura 2. Esto minimiza el overhead de Ray mientras habilita escalado horizontal a través de múltiples GPUs.
El corpus PDF ingresa a la arquitectura a través del Coordinador Ray, que particiona los archivos en batches balanceados basados en conteo de páginas—no conteo de archivos—asegurando distribución equitativa de carga de trabajo. Cada batch se despacha a un nodo worker independiente equipado con su propia GPU, donde el pipeline completo de la Arquitectura 2 se ejecuta sin modificaciones.
El patrón Pure Dispatcher
El coordinador Ray realiza exclusivamente orquestación a través de cinco pasos secuenciales:
1. Recepción: Recibe la solicitud de procesamiento conteniendo la lista de archivos PDF a procesar.
2. Particionamiento: Divide el corpus en K batches balanceados por conteo de páginas, asegurando que cada worker reciba aproximadamente la misma carga de trabajo independientemente del tamaño de los archivos.
3. Despacho: Envía estos batches a workers disponibles vía llamadas remotas.
4. Monitoreo: Espera a que todos los workers completen sus batches asignados.
5. Agregación: Consolida resultados de todos los workers en el output final.
Lo que Ray NO hace
Este diseño excluye explícitamente a Ray del pipeline de procesamiento:
• Ray no modifica parámetros del pipeline.
• Ray no procesa imágenes ni ejecuta inferencia OCR.
• Ray no sincroniza workers durante el procesamiento.
Cada worker opera independientemente una vez que recibe su batch, eliminando overhead de coordinación durante la etapa computacionalmente intensiva de OCR.
Configuración de workers
Cada worker encapsula una instancia completa de Arquitectura 2 con recursos dedicados:
Recursos por worker: 16 cores CPU + 1 GPU dedicada.
Pipeline: Idéntico a Arquitectura 2—ProcessPoolExecutor para paralelismo local con etapas completas de preprocesamiento, OCR y post-procesamiento.
Diseño stateless: Los workers reciben un batch, lo procesan completamente, retornan resultados, y no retienen estado entre invocaciones.
Este diseño habilita recuperación de fallos directa: si un worker falla, su batch puede reasignarse a otro worker sin efectos secundarios.
Escalado teórico
Con N workers, se espera que el tiempo de procesamiento escale como:
T_arch3 ≈ T_arch2 / N + T_overhead
Donde T_overhead representa el overhead de coordinación Ray (particionamiento, despacho, agregación), estimado en aproximadamente 5 segundos basado en mediciones de la Arquitectura 1.
Proyecciones de rendimiento

El sweet spot: 3 GPUs
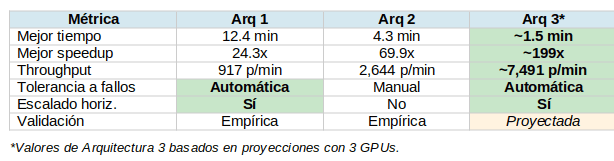
La configuración de 3 GPUs representa un objetivo de despliegue práctico, proyectando tiempo de procesamiento menor a 2 minutos mientras permanece dentro del presupuesto de hardware de una workstation high-end o servidor pequeño.
Más allá de este punto, el análisis costo-beneficio se vuelve menos favorable: mientras 12 GPUs podrían teóricamente procesar el corpus en 26 segundos, la inversión en hardware (~$20,000-30,000 USD) puede no justificar los ahorros marginales de tiempo para la mayoría de los casos de uso.
El sweet spot de 3 GPUs balancea costo, complejidad y rendimiento para despliegues de producción.
Justificación del escalado lineal
La asunción de escalado casi-lineal está justificada por la naturaleza embarazosamente paralela del procesamiento de documentos: cada worker procesa archivos PDF independientes sin comunicación inter-worker requerida durante la etapa computacionalmente intensiva de OCR.
El rol de Ray está limitado a particionamiento inicial y agregación final—operaciones que completan en segundos independientemente del tamaño del corpus.
Incertidumbres pendientes de validación
Estas proyecciones requieren validación empírica con hardware multi-GPU. Las incertidumbres clave son:
1. Contención de memoria GPU: ¿Afecta el rendimiento cuando múltiples GPUs high-end comparten recursos del sistema?
2. Ancho de banda PCIe: ¿Se convierte en cuello de botella al transferir grandes batches de imágenes a múltiples GPUs simultáneamente?
3. Overhead del dispatcher: ¿Permanece constante o aumenta con el conteo de workers?
Abordar estas preguntas establecerá la Arquitectura 3 como una opción de producción validada en lugar de un diseño teórico.
Ventajas y limitaciones
Ventajas
Velocidad: Hereda el procesamiento local optimizado de la Arquitectura 2.
Escalabilidad: Escalado horizontal casi-lineal agregando workers.
Tolerancia a fallos: Ray proporciona recuperación automática de workers.
Simplicidad: Los workers ejecutan código probado de Arquitectura 2 sin modificaciones.
Limitaciones
Costo de hardware: Requiere múltiples GPUs, aumentando significativamente la inversión inicial.
Validación pendiente: El despliegue multi-nodo requiere validación empírica antes de recomendarse para producción.
¿Cuándo usar esta arquitectura?
La Arquitectura 3 es la opción recomendada cuando:
• El tiempo de procesamiento es absolutamente crítico.
• Se dispone de hardware multi-GPU o se planea invertir en él.
• Se necesita escalado horizontal sin sacrificar velocidad local.
• Los picos de carga de trabajo son variables y requieren escalado elástico.
• Se desea tolerancia a fallos con el throughput de Arquitectura 2.
Comparación de las tres arquitecturas
Conclusión
La Arquitectura 3 representa el punto culminante de esta serie: combina lo mejor de ambos mundos. De la Arquitectura 1 hereda la tolerancia a fallos y el escalado horizontal vía Ray. De la Arquitectura 2 hereda la velocidad de procesamiento local optimizada.
El patrón Pure Dispatcher es la clave: al limitar Ray exclusivamente a orquestación y dejar que cada worker ejecute el pipeline optimizado sin modificaciones, se minimiza el overhead mientras se maximiza el throughput por nodo.
Con 3 GPUs, las proyecciones indican procesamiento de 11,368 páginas en aproximadamente 1.5 minutos—un throughput de ~7,500 páginas/minuto que rivaliza con clusters de producción de empresas grandes, pero ejecutándose en hardware accesible.
En el próximo artículo, abordaremos el trade-off entre velocidad y calidad: ¿cuánta precisión sacrificamos al usar 100 DPI en lugar de 300 DPI?
Próximo artículo: El trade-off DPI: ¿cuánta calidad sacrificar por velocidad?