
El trade-off DPI: ¿cuánta calidad sacrificar por velocidad?
12/23/2025

El trade-off DPI: ¿cuánta calidad sacrificar por velocidad?
Por Walter Milstein
Las arquitecturas propuestas utilizan PaddleOCR, un motor open-source, a baja resolución (100 DPI) para maximizar velocidad. Sin embargo, esto produce texto degradado que requiere post-procesamiento. Este artículo evalúa la calidad del pipeline completo (OCR + reconstrucción) contra un baseline comercial, cuantificando el trade-off fundamental entre velocidad y precisión.
El dilema de la resolución
La resolución de imagen, medida en puntos por pulgada (DPI), tiene un impacto directo y dramático tanto en calidad como en rendimiento:

Esta diferencia de 9x en volumen de datos se propaga a través de todo el pipeline: menos datos significa preprocesamiento más rápido, inferencia de red neuronal más rápida, y menor presión de memoria. El trade-off es precisión: menor resolución pierde detalles finos, afectando el reconocimiento de fuentes pequeñas y caracteres especiales.
Metodología de evaluación
Para cuantificar la degradación, comparamos dos enfoques:
Baseline comercial (ground truth): Azure Document Intelligence a 300 DPI.
Pipeline propuesto: PaddleOCR a 100 DPI + reconstrucción fuzzy.
¿Por qué Azure como ground truth?
Azure Document Intelligence fue seleccionado porque el corpus contiene documentos PDF generados digitalmente con capas de texto embebidas. Para tales documentos, Azure realiza extracción directa de texto en lugar de OCR, produciendo precisión esencialmente perfecta.
La inspección manual de aproximadamente 200 páginas muestreadas aleatoriamente confirmó que el texto extraído por Azure coincidía con el contenido original del documento sin errores observables. Esta validación establece el output de Azure como referencia confiable.
El pipeline de dos etapas
Nuestro pipeline opera en dos etapas para compensar la pérdida de calidad por baja resolución:
Etapa 1: Extracción OCR rápida
PaddleOCR procesa páginas a 100 DPI, produciendo texto con errores a nivel de caracter. Las confusiones comunes incluyen:
Confusión dígito-letra: "4" reconocido como "a", "0" como "o", "1" como "l" o "i", "8" como "B", "2" como "Z".
Ejemplo de texto corrupto: "Fech4: l4/02/2025" en lugar de "Fecha: 14/02/2025".
Corrupción de datos médicos: "Di4gn0stic0: Hipertens1on" en lugar de "Diagnóstico: Hipertensión".
Errores numéricos: "Ed4d: 5B 4ños" en lugar de "Edad: 58 años".
Etapa 2: Reconstrucción de texto
Una etapa de post-procesamiento corrige errores de OCR para producir texto usable. Evaluamos dos métodos:

GPT-4o logró calidad de reconstrucción significativamente superior, recuperando correctamente términos médicos, nombres propios y datos numéricos. Sin embargo, el overhead de latencia lo hace impráctico para procesamiento batch, donde fuzzy matching proporciona calidad aceptable con procesamiento casi instantáneo.
Métricas de calidad a nivel de caracter
Nota importante: El CER reportado mide la degradación introducida por nuestro pipeline optimizado para velocidad (100 DPI + reconstrucción fuzzy) relativa a un baseline comercial de alta calidad (Azure a 300 DPI con extracción directa de texto). No representa calidad absoluta de OCR, que varía significativamente por tipo de documento, calidad de imagen y características de fuente.
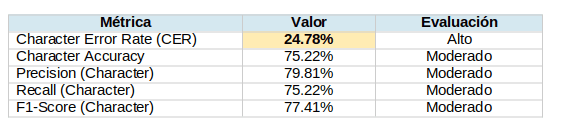
Métricas a nivel de palabra

El WER excediendo 100% indica que las correcciones a nivel de palabra requeridas exceden el conteo total de palabras, reflejando errores significativos de segmentación y reconocimiento a menor resolución.
Distribución de calidad entre documentos
El CER no es uniforme—varía significativamente entre documentos dependiendo de la calidad del escaneo original, tipos de fuente y complejidad del layout:

Esta distribución revela que aproximadamente 30% de los documentos logran calidad aceptable a moderada (CER < 25%), mientras el 70% restante requeriría procesamiento a mayor resolución para aplicaciones que demandan alta precisión.
Resumen del trade-off

Recomendaciones prácticas
Usar 100 DPI cuando:
• El objetivo es búsqueda semántica o alimentar sistemas RAG.
• El volumen de documentos es masivo y el tiempo es crítico.
• La precisión "suficientemente buena" es aceptable.
• Los documentos son formularios estándar con fuentes grandes.
Usar 300 DPI cuando:
• Se requiere transcripción de alta precisión (legal, médico, archival).
• Los documentos contienen fuentes pequeñas o caracteres especiales.
• El volumen es manejable y el tiempo no es la restricción principal.
• Los errores de OCR tienen consecuencias significativas.
Conclusión
El trade-off DPI representa una decisión arquitectónica fundamental. Nuestros resultados cuantifican precisamente esta decisión: 100 DPI proporciona 2.9x más velocidad a cambio de 24.78% de degradación CER.
Para aplicaciones de búsqueda semántica y RAG, donde el contexto importa más que la precisión caracter por caracter, esta degradación es frecuentemente aceptable. Para aplicaciones que requieren transcripción exacta, 300 DPI sigue siendo necesario.
El próximo y último artículo de esta serie proporcionará una guía práctica de selección: ¿qué arquitectura elegir según tu caso de uso específico?
Próximo artículo: Guía de selección: ¿qué arquitectura OCR elegir?